
Following a simple but structured plan to understand and manage data can help colleges and universities make the most of the data they collect.
Many institutions rely on data-driven decision-making to establish goals, plans, and initiatives to advance student success and outcomes. We look to business analytic tools to assist us. We find that rarely do all the data needed to make these decisions initiate from one system. This multi-sourced need requires us to integrate, aggregate, and transform the data to achieve the information results we desire. Above all, successful data-driven decision-making begins with good data.
The challenge to ourselves and institutional partners is to determine whether we have plans, processes, and tools in place to collect and store data securely, free from error or corruption, appropriately available for use, and removed or retired when no longer needed.
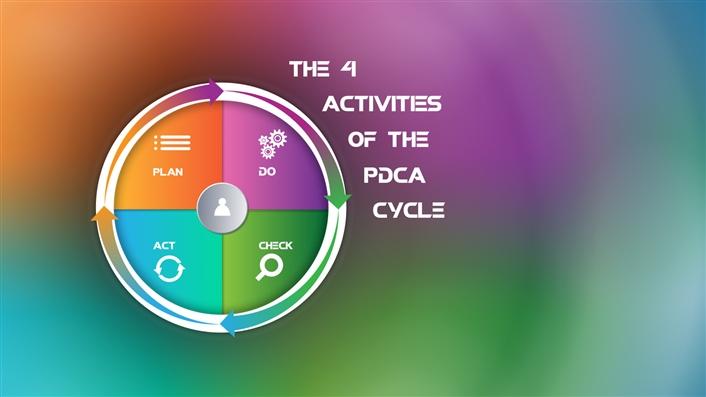
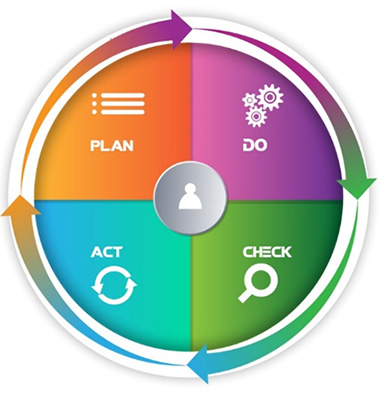
Institutions are great collectors of data, but are we good managers of those data? Do we place enough value in data integrity and regulatory requirements? Do we employ consistent practices to integrate and aggregate data from multiple systems ready for use in our decision-making processes? Using the Deming Cycle of plan/do/check/act, I've summarized a high-level approach for your consideration to ensure continuous improvement for the management of the data we use. The Deming Cycle provides a continuous quality-improvement model consisting of a sequence of four repetitive steps (see figure 1).
Credit: Tanakax3 / Shutterstock © 2018
Plan
- Develop the goals and objectives of the data collection. This should define the institution's need for the data.
- Reach agreement with institutional partners on operational definitions and methodologies. Determine what data are being collected and how they are being defined, entered, or recorded and disposed.
- Identify data sources, which could include manual data entry by people, acquired external organization data, scanned information, etc.
- Identify roles and responsibilities for ownership of data access and integrity (data stewards and brokers).
- Identify data classification, security, privacy, regulations, and standards practices required to support the data types collected and stored.
Now, you might say, "Well, why do I need to do all these steps before collecting my data? I know what data I need." Let's look at the collection requirements for something that may seem obvious—the data field "Name." What's in a name? A rose by any other would smell just as sweet. This is wonderful for Shakespeare, but the rest of us must be accountable for actual people's names and how "Name" data interact with systems and business processes.
University of the Pacific defines the purpose for collecting Name as "to identify a person associated with our campus in our systems." The "Name" field does not stand alone. Systems typically include additional fields that are part of a person's full name: First Name, Last Name, Preferred First Name, Preferred Last Name, and Chosen Name. Having a person's "Name" alone does not provide us with information we may need to verify a person's identity or interact with that individual. For example, the absence of a preferred or chosen name could violate privacy of transgendered or LGQBT students. To further characterize the "Name" field, we employ data-entry rules to provide standards for manual entry through the use of uppercase and lowercase letters and hyphens. If a "Name" needs to be changed, there are processes that require specific documents to validate the change. We may also want to share the field of "Name" with other systems requiring the ability to match fields through crosswalks and APIs. The reasons above dictate the necessity of good planning for our data collection.
Do
- Create security profiles to enable appropriate access to data and information.
- Train staff on best practices for data entry, management, access, and disposal.
- Implement collection systems that provide a great and secure customer experience.
- Manage databases and storage systems to ensure data are securely ready for intended use.
- Formalize extract, transform, and load processes across systems.
- Process the data to be incorporated into the management of academic and administrative work.
- Create new data values and information through use of analytic modeling techniques.
- Employ useful output mechanisms to enable improved consumption by users.
- Adhere to applicable government regulations such as GDPR.
- Evaluate the use of the data to determine if they should continue to be collected.
Check
- Put into place audit practices that monitor data for errors, duplicates, corruption, and breaches.
- Assess current data practices and models for improvement and change.
- Assess the lifespan of data to ensure retention requirements are met.
Act
- Actually use the data in decision-making. Too often we are still not using the full value of the information available through our analytic tools to assist us in our decision-making.
- Stop collecting data that are not needed or used.
- Archive or dispose of data based on your institution's defined data policy and retention standards.
- Hold regular meetings with data owners/stewards/brokers.
- Update processes, training, and standard practices to reflect the feedback from the auditing and monitoring practices.
A cycle of continuous improvement increases not only the value of our data but also of our people, our work, our decisions, and ultimately student success.
This is part of a collection of resources related to how colleges and universities can use systems integrations or implementations to make information-based decisions through improved analytics. For the full set of resources and tools on this topic, go to Using Analytics to Answer Important Institutional Questions.
Peggy Kay is Assistant Vice President, Technology Customer Experience, University of the Pacific.
© 2018 Peggy Kay. The text of this work is licensed under a Creative Commons BY-NC-ND 4.0 International License.