
Institutions that hope to use analytics to make better decisions must develop the architecture and processes to work efficiently with data from disparate sources.
In order to use data to answer questions, the data must be made available to decision makers, and a significant part of building any analytics program is the ingestion of data. In previous decades, this was not terribly difficult because data typically resided in on-premises databases, making the ingestion process relatively simple—connect to the database and extract the data you need. Of course, the process of cleansing and transforming those data into a structure that made analysis possible still required lots of effort, but the big battle of data acquisition had already been fought and won.
The introduction of cloud services, however—including public cloud offerings such as Amazon Web Services (AWS), software-as-a-service (SaaS), etc.—has complicated this significantly. As more and more higher education institutions begin to implement solutions like Workday, Slate, and a variety of other cloud-based applications, direct access to databases is no longer an option, so these institutions must completely rethink their systems-integration philosophies as well as the technology platforms that undergird them.
Bucknell's Transition
A couple of years ago, Bucknell University was facing this exact challenge. The institution was in the process of transitioning away from a single, monolithic enterprise system—one that handled everything from admissions and financial aid to finance and advancement—to a "best of breed" model that gave each division an opportunity to invest in the best possible solution to meet the institutional needs. But "best of breed" comes at a cost, particularly integration. Indeed, the battle between "best of breed" and "best of integration" rages on!
So, how can we perform data integration between applications that can be running on-premises, in the public cloud, or SaaS? Enter the enterprise service bus (ESB).
MuleSoft, the vendor we would eventually choose, defines an ESB as follows:
An Enterprise Service Bus (ESB) is fundamentally an architecture. […] The core concept of the ESB architecture is that you integrate different applications by putting a communication bus between them and then enable each application to talk to the bus. This decouples systems from each other, allowing them to communicate without dependency on or knowledge of other systems on the bus. The concept of ESB was born out of the need to move away from point-to-point integration, which becomes brittle and hard to manage over time. Point-to-point integration results in custom integration code being spread among applications with no central way to monitor or troubleshoot. This is often referred to as "spaghetti code" and does not scale because it creates tight dependencies between applications.
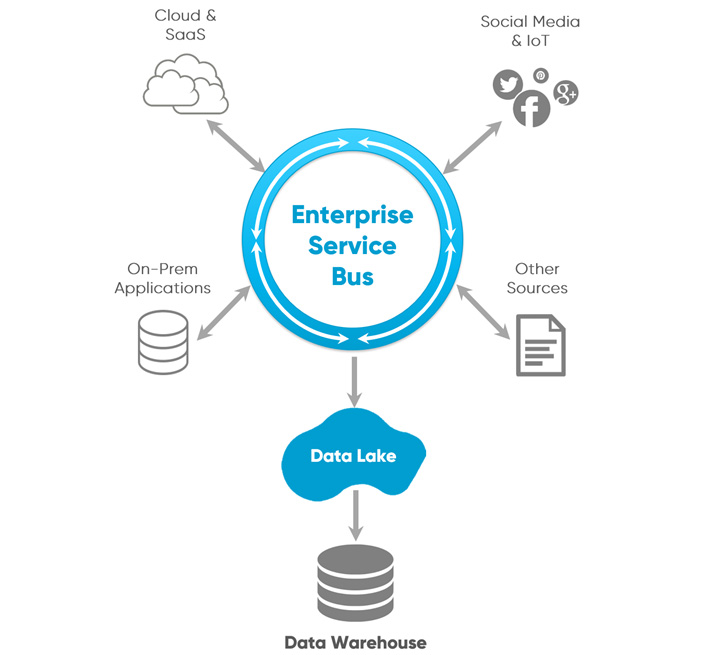
Thus, an ESB would be a critical part of our strategy moving forward (see figure 1). It allowed us to move away from point-to-point integrations to a scalable, well-managed integration platform. Though our SasS platforms do not allow direct database communications, the ESB allowed us to easily consume web services to read and write data to and from the application. Since web services provide an abstraction layer from the underlying technical details and code being invoked, it became our standard, even in situations where a database is directly available. Why, for instance, would we choose to write directly to multiple tables in a database to perform some transaction when we can call a web service that executes the entire unit of work without the need for us to understand all the underlying database schemas? By moving to a web-services-first model, the location of an application became irrelevant, allowing us to be agnostic about where applications are implemented.

What about Analytics?
The ability to move data from system to system allowed those applications to communicate seamlessly with each other, but we still needed to get large amounts of data out of those systems and into our data platform so we could perform the reporting, visualization, and analysis required to enable data-informed decision-making. Adding more complexity to this problem, many of our enterprise systems do not store data in traditional relational database formats, so data are often retrieved in loosely structured JavaScript Object Notation (JSON) files. How do we go from JSON to the heavily structured format typically used in data warehouses? The answer for us was a data lake that sits between our ESB and our traditional enterprise data warehouse (see figure 2).
The key was that this platform be nimble, easy to use, and capable of handling both structured and unstructured data. Rather than deal with the complexity of something like Hadoop, we chose a nimble, easy-to-use platform from one of the top NoSQL vendors, MongoDB. Moreover, because of our previously mentioned agnosticism, we were able to leverage their cloud-based database-as-a-service offering, MongoDB Atlas, which pushed the management of the database to the vendor and allowed us to focus on building our data integrations rather than building the technical skill sets required for a new and unfamiliar database platform.
By implementing this data lake, our integration developers no longer needed to put much thought into the structure of the data. They could simply land the data there, largely as is. From there, it is the job of the business intelligence developers to add the required structure to the data and transform those data into a more traditional format required by the data warehouse.
But the data lake is more than just a simple staging area for unstructured data on their way to the data warehouse—it will, over time, become a rich repository of data that can be leveraged by the university for any number of data science and ad hoc use cases.
Summary
Bucknell has had this new architecture in place for over two years now, and we have successfully completed integrations between numerous cloud and on-prem systems. More importantly, we've established a platform that is flexible and scalable to meet our future needs—it can handle any application, in any location, and with any structure of data. To be sure, philosophical and architectural changes of this nature are never simple—they inevitably come with bumps in the road. But it has proven to be the right move for Bucknell, making integration between systems and to the data warehouse more standardized, flexible, and scalable than ever before.
This is part of a collection of resources related to how colleges and universities can use systems integrations or implementations to make information-based decisions through improved analytics. For the full set of resources and tools on this topic, go to Using Analytics to Answer Important Institutional Questions.
Ken Flerlage is Business Intelligence Functional Architect at Bucknell University.
© 2018 Ken Flerlage. The text of this work is licensed under a Creative Commons BY 4.0 International License.