
If the GLAM sector does not express its collections in linked data, it will not have a voice in the evolving forms of discovery and preservation being made possible by this global, interrelated collection of data.
"If linked data is so important, why isn't everyone using it?"
"Libraries need to express their collections as linked data. . . . It's one of the most important web technologies."
I have heard both of these statements during meetings this year, but for me, they seem to be at odds with one another. Linked data has been discussed since the beginning of the World Wide Web 30 years ago (i.e., the so-called semantic web). For something potentially so important, this begs the question: Why hasn't linked data more directly affected galleries, libraries, archives, and museums (aka GLAM)?
The following definition of linked data comes from Wikipedia: "A method of publishing structured data so that it can be interlinked and become more useful through semantic queries." Essentially, linked data has been proposed as the means by which the web can move from being a collection of documents to a global data space where people and machines can not only discover data but understand and infer the associated relationships.
Tim Berners-Lee, known as the inventor of the web, listed four principles for linked data:
- Use URIs to name (identify) things.
- Use HTTP URIs so that these things can be looked up (interpreted, "dereferenced").
- Utilizing open standards such as RDF and SPARQL, provide useful information about what a name identifies when it's looked up.
- When publishing data on the web, refer to other things using their HTTP URI-based names.1
Furthermore, in 2009 Berners-Lee offered three "extremely simple" rules for linked data:
- All kinds of conceptual things, they have names now that start with HTTP.
- If I take one of these HTTP names and I look it up . . . I will get back some data in a standard format, which is kind of useful data that somebody might like to know about that thing, about that event.
- When I get back that information, it's not just got somebody's height and weight and when they were born, it's got relationships. . . . And when it has relationships, whenever it expresses a relationship, then the other thing that it's related to is given one of those names that starts with HTTP.2
While these principles and rules may seem simple, they belie a complex set of data models, schemas, and ontologies, particularly related to RDF. RDF is a highly canonical, schema-less model that can support powerful search, interpretation, and relationships. However, both the learning curve and the implementation path for RDF are steep.3
In recent years, several developments have lowered the barrier to entry (with perhaps a corresponding trade-off in capability) to linked data. Though the metaphor may be crude, this is similar to the early debates regarding SGML and HTML. SGML provided greater capability for processing and interpreting web-based content, but the advent and the proliferation of HTML provide evidence that ease of use fosters adoption more effectively.
Rob Sanderson, semantic architect for the J. Paul Getty Trust, affirmed this point in 2016 when he noted that if developers cannot adopt or leverage an approach for linked data, that approach is unlikely to gain much traction. He elaborated that if one has to choose among the triad of complete, usable, and accurate, choosing usable will result in the most traction and highest adoption. Sanderson noted that the International Image Interoperability Framework (IIIF) Presentation API, Schema.org, and the Europeana Data Model are good examples of the balance between complete, usable, and accurate.4
OCLC's International Linked Data Survey of the library community provides evidence of the growing use of linked data, though it notes use within sectors such as e-commerce, medicine, scientific research, and government services in addition to growth within research institutions and cultural heritage organizations. It is worth adding that OCLC also identified responses from service providers and the presence of linked data projects in production for at least four years, both signs of a maturing landscape.5
At the 2018 ASIST conference, Matt Mayernik from the National Center for Atmospheric Research described a useful framework for classifying linked data tools and services. Looking both retrospectively and prospectively, Mayernik identified four categories: Relationship Identification; Relationship Validation; Relationship Characterization; and Relationship Preservation. One of the linked data services Mayernik identified in the Relationship Preservation category is RMap, developed by my institution—the Sheridan Libraries at Johns Hopkins University—in partnership with IEEE and Portico through a grant from the Alfred P. Sloan Foundation. RMap, which is based on a flattened or simplified version of the OAI-ORE protocol, expresses and preserves the map of items related to a scholarly work. The current RMap service contains information graphs related to IEEE's article database.
A sample "DiSCO" (Distributed Scholarly Compound Object) from a search of "engineering" is depicted below:
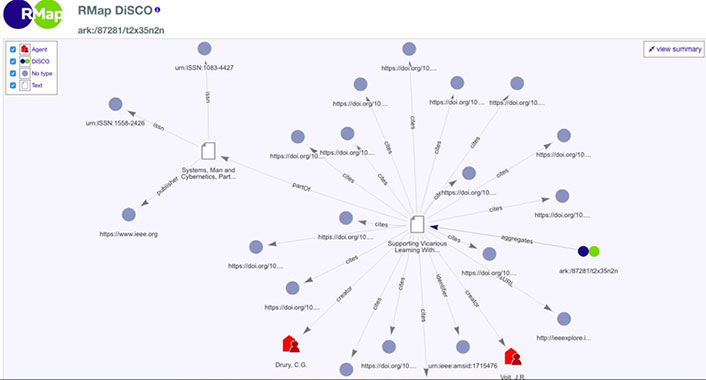
The nodes in this graph represent individual articles or agents (e.g., authors) and the links between the nodes describe the associated relationships (e.g., cited by). Perhaps equally important, DiSCOs can be versioned in a persistent manner, thereby providing a mechanism for tracking provenance and the evolution of a work and its components over time.
The Sheridan Libraries is applying RMap in additional ways through the Black Press in America (a collaboration with the Johns Hopkins University Press Project MUSE) and the Archaeology of Reading (a project funded by the Andrew W. Mellon Foundation). For the Black Press in America, RMap will be used to identify the connections between print books, open ebooks, and content presented through a customized Mirador application, which is an IIIF-compliant viewer. For the Archaeology of Reading, RMap is being used to display "research findings" or pathways of exploration through the digital content. A research finding is defined as "an ordered list of actions taken by the user in a certain state." By mapping research findings, scholars will be able to keep track of their own exploration through digital resources, share those explorations with others (especially for teaching and learning), and maintain a record of those explorations. In this case, the nodes within the graph represent different states of the viewer or application, and the links between them represent the pathways.
The image below depicts a sample research finding generated by RMap:
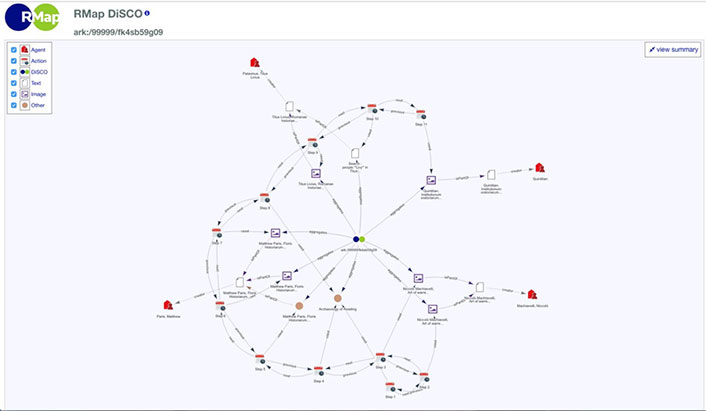
RMap represents one possible approach for linked data applications in the GLAM sector. The Association of Research Libraries recently issued a draft white paper focused on possible collaboration with WikiData. The Arches project at the Getty Conservation Institute represents another application with a museum collection focus. But rather than identifying a comprehensive list, I would like to point out the growing use and possibilities of linked data within the GLAM sector.
While the lower barrier to entry approach (including RMap) has fostered greater adoption of linked data, I believe that if any community should embrace the higher degree of challenge associated with a full implementation of RDF-based approaches, it should be the GLAM sector. The disadvantage of lightweight linked data approaches is that they are often context-specific or raise challenges with migration or do not account for provenance or persistence. The GLAM sector in particular should care about a global, comprehensive approach with a foundational underpinning of preservation when considering linked data.
Returning to the two statements at the beginning of this column, I'd like to note that while not everybody is using linked data, there are clearly more organizations and applications, particularly from the private sector, that are doing so. Every time our community uses a Google service, we contribute to its information graph—and Google is not sharing those graphs back with us. Perhaps the more relevant question is: "If linked data is so important, why isn't it being more broadly utilized in the GLAM sector?"
As for the second statement, when I first joined the research library at Johns Hopkins, I noted a handout for our students that stated: "Why you should use the library instead of Google." At this point, everyone in the GLAM community would agree that if collections do not appear in a Google search, they are largely invisible. Very soon—if not even now—if collections do not appear on an information graph, they will be largely invisible. If the GLAM sector does not express its collections in linked data, it will not have a voice in the evolving forms of discovery and preservation being made possible by this global, interrelated collection of data.
Notes
- Tim Berners-Lee, "Linked Data" (website), July 27, 2006 (updated on June 18, 2009). ↩
- Tim Berners-Lee, "The Next Web," TED2009 (February 2009). ↩
- Tom Heath and Christian Bizer offer a useful description for implementing linked data based on RDF in chapters 4 and 5 of their book Linked Data: Evolving the Web into a Global Data Space, Synthesis Lectures on the Semantic Web: Theory and Technology (Williston, VT: Morgan & Claypool Publishers, 2011). While useful, the description also provides evidence regarding the complexity of such an implementation. ↩
- Rob Sanderson, "Community Challenges for Practical Linked Open Data," December 15, 2016. ↩
- For a summary of this OCLC survey, see Karen Smith-Yoshimura, "Wrapping Up the 2018 International Linked Data Survey for Implementers," Hanging Together (blog), December 5, 2018. ↩
Sayeed Choudhury is Associate Dean for Research Data Management and Hodson Director of the Digital Research and Curation Center (DRCC) at Johns Hopkins University.
© 2019 Sayeed Choudhury. The text of this article is licensed under the Creative Commons Attribution 4.0 International License.
EDUCAUSE Review 54, no. 1 (Winter 2019)