
An analytics program at Pontificia Universidad Javeriana Cali uses machine learning and big data techniques to identify in a timely manner those students who are at risk of dropping out and then apply preventive actions to try to keep those students enrolled.

Pontificia Universidad Javeriana, founded in 1623, is part of 186 universities worldwide entrusted to the Society of Jesus. The Times Higher Education has ranked the institution as #1 in Colombia and #3 in Latin America. The institution has two campuses, one in Bogotá and one in Cali. The Cali campus has approximately 8,500 students and offers twenty-four undergraduate programs, forty graduate academic programs, and three doctorates.
In 2012, Pontificia Universidad Javeriana Cali established its institutional strategic plan, which defines goals around academic and human excellence, internationalization, research, innovation, social responsibility, and sustainability. In response, a strategic information technology plan was established to develop the skills and competencies necessaries to help achieve those goals. One objective was to strengthen decision-making processes by facilitating timely access to accurate and institutionally defined information, and this objective prompted the institution to launch a project on predictive analytics that uses machine learning and big data.1
Statistics on college and university dropouts worldwide are worrisome. In the United States, the rate is around 40%; Europe is at about 60%, and Asia and Latin America are both at about 50%.2 On August 1, 2019, The College Dropout Scandal was published, presenting a sharp criticism of this situation, asking who should be accountable for it.
Higher education institutions pursue a multitude of activities to try to reduce student dropout, including financial aid, academic counseling, writing centers, pedagogical support centers, and centers for physical or cultural events.3 The problem lies in being able to determine, as early as possible, which students are at risk of dropping out.4 Therefore, Pontificia Universidad Javeriana decided to use its predictive analytics tool to pilot a project that predicts student dropout probability.
Methodology
Conventional technology projects carry high expectations for achieving their stated goals, and management therefore focuses on getting those projects done on time and within budget. In contrast, predictive analytics projects behave more like research projects for which the uncertainty level is much higher. Thus, methodologies tend to be nonlinear, as it is the case with CRISP-DM5 or Arcitura, in which a set of tasks is described in a general, linear way but can be executed in different order, often requiring some backtracking to previous tasks based on reached results.
The first step is to clearly define the goal. A clear goal allows determining what information to use, how to measure when the goal has been reached, and clarify the learning type to be applied (supervised learning in this case, as opposed to unsupervised learning in which no goal variable is defined). Then, families of hypotheses that might explain the situation are developed, in conjunction with the data available—whether inside or outside the institution—that supports those hypotheses. In our case, the goal was to calculate—by the first day of each semester—the dropout student probability with a ROC-AUC6 higher than 90% (ROC-AUC is a performance measure of how robust a model is). Table1 shows some examples of the hypotheses about dropout rates and the kinds of data that could help test those hypotheses.
Table 1. Hypotheses and data that support them (not an exhaustive list)
|
Hypothesis Explaining Dropouts |
Examples of Support Data |
|---|---|
|
Academic issues |
Courses, grades, courses order, student demographics, professor demographics, course size, course heterogeneity, GPA |
|
Student-institution empathy |
Student participation on cultural, academic, and extracurricular activities; class attendance |
|
Financial situation |
Nonperforming-loan information, scholarships |
|
Pedagogical problems |
Student attendance to writing centers, number of interactions with counselors, professor expertise, professor professional development |
|
Vocational orientation |
Student state exams results, school grades, core courses grades, academic counseling attendance |
|
Others |
Taking courses with known professors, taking courses with known classmates, student demographic data |
We then proceed to collect, unify, clean, and transform the data into the appropriate format for feeding into machine learning algorithms.
A feature-generation activity is conducted looking for ways to produce new information from the existing data, which can help algorithms determine patterns quickly.7 For example, data about what courses a student has taken can be used to generate new information about how heterogeneous those courses were in terms of the background disparity of fellow students. Nevertheless, an excess of variables can lead to overfitting models, reducing their predicting power. Therefore, a feature-selection stage is needed to eliminate undesirable variables.8 Common techniques include statistical, weight, wrapper, and dimensionality reduction.
Finally, a modeling/validation stage consists of testing a selected machine learning algorithm database, looking for those algorithms with the strongest predictive power. To be able to compare the algorithms, a validation mechanism is defined, generally based on the goal established at the beginning. It is common to proceed with an optimization stage in which various parameter values are tested on each algorithm, using different techniques to improve results further.
The value of analytics projects is not in the prediction but the use made of It. Therefore, it's essential to work closely with domain experts who can translate institutional needs to technical requirements and particularly to determine how to apply solutions to selected problems. Users tend to expect prescriptive analytics (what to do) instead of predictive analytics (what will happen). Nevertheless, most predictive algorithms tend to be the obscure ones (deep learning, gradient boosted trees, etc.).9 As a result, answering why a model made a specific prediction can be a challenging task. Thanks to GDPR and other privacy regulations, a new and promising branch called Explainable Artificial Intelligence is under development, which seeks to explain such predictions in a more understandable way.10 Nontechnical people tend to view machine learning projects with suspicion and therefore they try to avoid using them, a situation that can be handled using change management techniques, including training.
Deliverables
Five deliverables are handed out to users (counselors, academic leaders, etc.).
- Predictive power of each selected model: We use ROC-AUC curves as described above.
- Dropout probability per student: For each student, the dropout probability is calculated, making it easy to identify at-risk students. Because these predictions are computed each semester for each student, it is also possible to identify trends. If a student's probability of dropping out is growing faster than desired, for example, that student can be marked as "at risk" even if the student has not reached a predefined threshold.
- Variables supporting prediction per student: For each student prediction, a set of variables that support the forecast is described using explainable artificial intelligence algorithms. This information helps users determine the course of action to take individually.
- Variables supporting prediction per major: Typical variables that appear on a set of students are also described to allow users to pick general instead of individual activities to apply.
- What-if simulation environment: Finally, a what-if simulator enables users to test change of variables values and observe dropout probabilities responses. This artifact aims to help users explore new possible dropout explanations, although because the number of used variables (more than 5,000 easily) it is not easy to use.
Lessons Learned
From this pilot program, we learned several important lessons about how to use machine learning and predictive analytics to address the problem of dropout rates in higher education.
-
It is possible to determine—on the first day of each semester—the dropout probability for all of our 7,000+ undergraduate students, reaching accuracy levels 93% on average for several academic programs of our four schools (see figure 1).
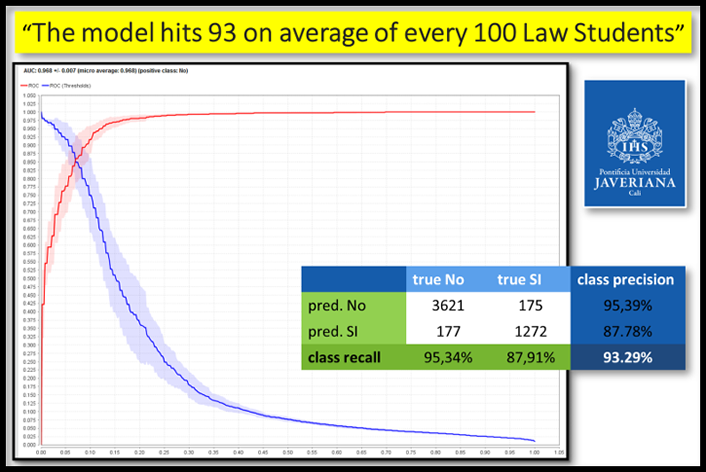
Figure 1. Example of evaluation for Law Academic Program - This result can be reached using standard information already captured by administrative software for higher education as Banner or PeopleSoft plus some minor extensions.
-
Users with academic backgrounds in psychology tend to know what to do with the provided information. Providing training in counseling techniques for users with different kinds backgrounds could therefore be a valuable practice. Figure 2 shows a dashboard that can be used to make decisions to try to reduce dropout. It shows the number of students with a probability prediction higher than 50% (orange) versus those with low probability (blue), by semester (left) and number of terms since enrollment (right). Also, the probability prediction is shown for each student by term (lower part).
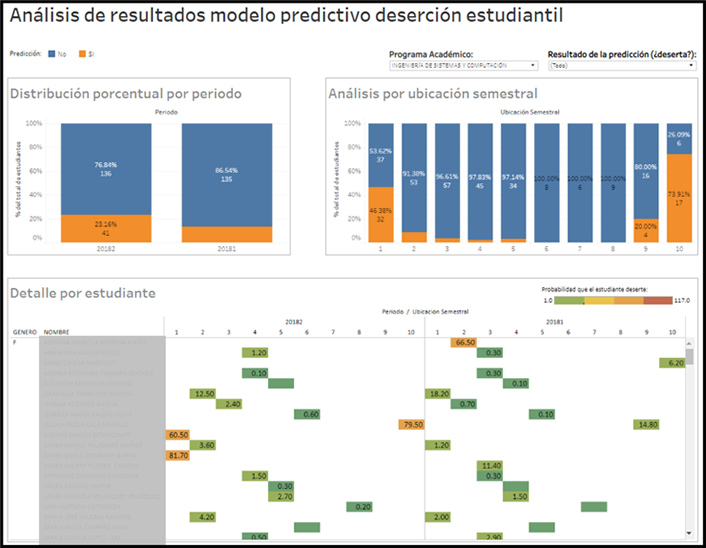
Figure 2. BI Dashboard for helping academic leaders make decisions - Even if an institution is not planning to develop machine learning projects by itself, it is very important to know how to do this kind of project, in particular how to evaluate models correctly. Otherwise the institution wouldn't know how risky it would be to make decisions based on the predictions.
- IT departments are in an advantageous position to generate value through executing machine learning-based projects since they understand the "business" and have access to both the data and the infrastructure required to run these types of projects. Knowing how to do machine-learning projects also prepares IT departments to control contracts with third-party companies hired to execute those projects.
- Because high demands for memory, processing, and GPU (graphics processing units—a new kind of processor that accelerates graphics and machine learning processes) are common on machine-learning projects, cloud computing becomes a viable alternative.
- It's a good idea to use machine-learning platforms that support project management methodologies and, as much as possible, automate repetitive tasks and thereby avoid some amount of coding that would otherwise be needed.
- We are working on predicting enrollment demand for specific courses and a pilot on predicting academic performance, also using machine-learning projects. Other departments are asking to explore machine-learning projects on marketing and financial data.
In summary, using machine learning to predict academic dropout with high accuracy is not only possible but suitable. It requires information already captured by most colleges and universities; good platforms already exist to support the development of this kind of project; and the required technical training for IT department is relatively low.
The article is part of a set of enterprise IT resources exploring the role of digital transformation through the lens of analytics. Visit the Enterprise IT Program to find resources focused on digital transformation through additional lenses of governance and relationship management, technology strategy, understanding costs and value, and analytics.
Notes
- John Edwards, "What Is Predictive Analytics? Transforming Data into Future Insights," CIO.com, August 16, 2019; Jay Boisseau and Luke Wilson, "Enterprise AI: Diving into Machine Learning" [https://www.cio.com/article/3390738/enterprise-ai-diving-into-machine-learning.html] CIO.com, April 24, 2019; and Cecilia Earls, "Big Data Science: Establishing Data-Driven Institutions through Advanced Analytics," EDUCAUSE Review, May 6,, 2019. ↩
- Betsy O. Barefoot, "Higher Education's Revolving Door: Confronting the Problem of Student Dropout in US Colleges and Universities," Open Learning 19, no. 1 (February 2004), 9–18; Ulrich Heublein, "Student Drop-out from German Higher Education Institutions," European Journal of Education 49, no. 4 (October 23, 2014), 497–513; Marie Duru-Bellat, "Access to Higher Education: The French case," January 2015; UNESCO, "Higher Education in Asia: Expanding Out, Expanding Up. The Rise of Graduate Education and University Research," 2014; and Carolina Guzmán Ruiz et al., "Educación Superior Colombiana," Ministerio de Educación Nacional de Colombia, 2009. ↩
- MinEducación, "Política y Estrategias Para Incentivar la Permanencia y Graduación en Educación Superior 2013-2014," vol. 57, no. 1, pp. 1–24, 2013. ↩
- Hanover Research, "Early Alert Systems in Higher Education," November 2014. ↩
- See "What Is the CRISP-DM Methodology," Smart Vision Europe; and Rüdiger Wirth and Jochen Hipp, "CRISP-DM : Towards a Standard Process Model for Data Mining," Proceedings of the Fourth International Conference on the Practical Application of Knowledge Discovery and Data Mining, January 2000. ↩
- Jason Brownlee, "How to Use ROC Curves and Precision-Recall Curves for Classification in Python," August 31, 2019. ↩
- Guozhu Dong, "A Quick Guide to Feature Engineering," KDnuggets, February 2019. ↩
- Jie Cai, Jiawei Luo, Shulin Wang, and Sheng Yang, "Feature Selection in Machine Learning: A New Perspective," Neurocomputing 300 (March 2018), 70–79. ↩
- Alexander Lavin, "Interpreting AI Is More Than Black and White," Forbes, June 17, 2019. ↩
- Filip Karlo Došilović, Mario Brcic, and Nikica Hlupic, "Explainable Artificial Intelligence: A Survey," May 2018. ↩
Jaime A. Reinoso is the director of the Centro de Servicios Informáticos (CSI) at Pontificia Universidad Javeriana Cali.
© 2019 Jaime A. Reinoso. The text of this work is licensed under a Creative Commons BY 4.0 International License.