
Key Takeaways
- The possibility of a new method of operation for the web is built with linked open data, which dynamically connects one piece of discrete data to another, not just pages to pages.
- The Linked Jazz research project explores the application of linked open data to materials held or curated by libraries, archives, and museums.
- Linked Jazz focuses on jazz history, but the tools and methods developed by the team are meant to be domain-agnostic.
- The long-term goal of the Linked Jazz project is to build a platform for tools that demonstrate the various ways linked open data can be used to connect the data sets culled from disparate archives and libraries.
Leanora Lange is the processing and institutional archivist and digitization projects liaison at the Center for Jewish History. Cristina Pattuelli is an associate professor at the School of Information and Library Science at the Pratt Institute.
Linked open data represents an exciting frontier for digital scholarship, offering the possibility of the web functioning in a whole new way: connecting not just one page to another, but one piece of discrete data to another, dynamically. This new web capability will not thrive without the work of research teams dedicated to finding out how to make the data currently held in dispersed, individual silos — such as library catalogs, archival finding aids, and digitized books and records — available for integrated access as linked open data.
By supporting the use of linked open data and participating in linked open data research and development, libraries, archives, and other nonprofit or mission-driven institutions dedicated to providing equitable access to information have an opportunity to expose their resources to a wider audience of users.
Research into the possibilities for linked open data applications within digital scholarship remains wide open. While a number of research projects are currently exploring methods and tools to clean and open up data for use in linked open data environments, the field of digital scholarship lacks a critical mass of these efforts. To describe how a linked open data project works — and to call others to action — this article presents a case study of Linked Jazz, an education-focused project about jazz history in which team members research and develop applications of linked open data and encourage others to become involved in related scholarship.

Figure 1. Linked Jazz home page
What Is Linked Open Data?
Linked open data is a method of connecting distinct pieces of data in a meaningful way that can be read by a computer and disseminated on the web. Where humans understand the statement "Mary Lou knows Thelonious," a computer just sees a string of text. Linked open data allows us to specify which Mary Lou we mean, as well as which Thelonious. This is done by connecting a string of text ("Mary Lou Williams") to a Unique Resource Identifier (URI).
A URI looks like the familiar URL, but a URI designates a unique piece of data, such as the identity of an individual, and it remains stable across time. Some of the most typical sources of URIs come from the Library of Congress Linked Data Service1 and DBpedia,2 a sister of Wikipedia that culls structured data from Wikipedia. For example, a URI for Thelonious Monk is http://id.loc.gov/authorities/names/n82218969, and for Mary Lou Williams, http://dbpedia.org/resource/Mary_Lou_Williams.
Linked open data also employs ontologies that connect URIs in a meaningful way. Ontologies function as the list of possible verbs to add to a sentence or, in linked open data terms, the possible predicates. For example, the Friend of a Friend (FOAF) ontology could be used to describe individuals. This ontology lists knows as a possible predicate. The Relationship vocabulary offers many more options, such as close friend of, child of, or mentor of.
Using a predicate, we could say "Mary Lou Williams knows Thelonious Monk," with each of the three pieces of that statement referring to a set URI or predicate from an ontology that a computer can understand. By connecting these three distinct pieces of data in a meaningful way, we have made the jump from disconnected data to meaningful information.
Linked open data has been heralded as the basis of the next web, which will be a web not of document-like web pages that link from one page to another but a web of data that interact dynamically. A few applications of linked open data to cultural heritage materials already exist. One of the most notable is Europeana, an effort to create a portal to the cultural heritage materials held in libraries, archives, and museums throughout Europe. A similar effort in the United States is the Digital Public Library of America (DPLA), which aggregates in a single portal the metadata and thumbnails of images from digital collections of libraries, archives, universities, museums, and other institutions. Far from being just another silo of information, DPLA is working to generate a robust way in which the metadata it aggregates can be offered to others as linked data.
What Is Linked Jazz?
An introduction to the Linked Jazz project (6:37 minutes).
Linked Jazz is a research project based at the Pratt Institute School of Information and Library Science that explores the application of linked open data to materials held or curated by libraries, archives, and museums. Linked Jazz focuses on jazz history, but the tools and methods developed by the team are meant to be domain-agnostic. Tools, presentations, and papers can be found at the project website.
Linked Jazz is an educational project at its core. It approaches linked open data research in a way that provides educational opportunities for all participants, from the project team to the volunteers completing tasks on our crowdsourcing tool, while ultimately aiming to contribute to the larger landscape of linked open data research.
Phase 1: Mapping Names
Linked Jazz began as an exploratory project that extracted personal names from oral history transcripts held in jazz archives. These personal names were then matched with corresponding URIs. This mapping created a data set of more than 9,000 jazz artist names and associated URIs.3
Using the data set of names, base-level relationships among the artists could be determined by assuming that if one artist mentions another in an interview, the first artist knows the second. Using the relationship knows to connect artists in this way, a basic social network could be established. This network was used to create the Linked Jazz Network Visualization Tool. Far from presenting a static network, this tool allows users to dynamically interact with the network, zoom in to see clusters, choose one artist in order to see just his or her social network, and dynamically create networks for specific individuals.4
Phase 2: Crowdsourcing Relationships
The second phase of the Linked Jazz project has been to develop tools and methods to map the social and professional relationships of jazz artists whose names appear in our data set. While the team demonstrated that a basic social network could be determined by linking names using the relationship knows, there was an opportunity to develop a tool that pushed linked open data a step further to describe the types of relationships shared among jazz artists.
Linked Jazz 52nd Street, a tool created by team member Matt Miller, uses crowdsourcing to gather insight into the relationships shared by the jazz artist community. In this tool, users see snippets of text from an oral history interview in which the interviewee, usually a jazz great, mentions another person, often another jazz artist (figure 2). The user is asked to identify the relationship that the interviewee shared with this person from a set list of possible relationships. The tool tallies the responses and creates a data set that states these relationships (for example, "Mary Lou Williams was a close friend of Thelonious Monk") in a machine-readable manner.
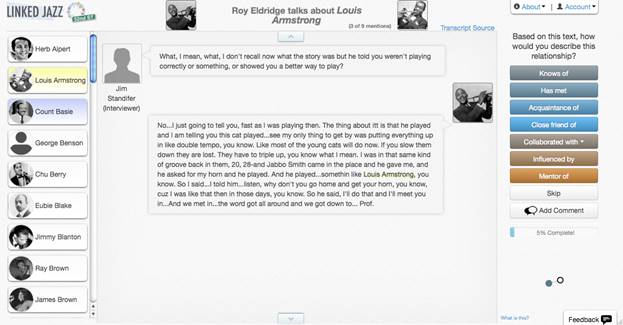
Figure 2. Task interface of Linked Jazz 52nd Street tool
The development of Linked Jazz 52nd Street provides a particularly strong example of learning by doing, and it moved forward in an iterative fashion. The team's main task was to build a crowdsourcing tool that would (1) attract users, (2) retain users, and (3) generate quality data. To meet these goals, we researched the existing literature on crowdsourcing and modeled our tool on some of the best practices we identified in existing tools. We chose crowdsourcing for this tool because it combines automated techniques that can generate a robust social network with the human ability to understand texts and identify the nature of personal and professional relationships described in them.
To address the concerns of attracting and retaining users, we needed to understand what motivates users to participate in a crowdsourcing project, and then sustain this motivation. Methods of creating initial interest that we built into Linked Jazz 52nd Street include:
- An attractive, welcoming landing page (figure 3)
- Easy-to-follow steps of how to get started
- Eye-catching images of jazz artists to click on to start
- An "About" section that does not navigate away from the main landing page but rather appears in a lightbox over it (figure 4)
- An interactive tutorial for first-time users (figure 5)

Figure 3. Linked Jazz 52nd Street landing page
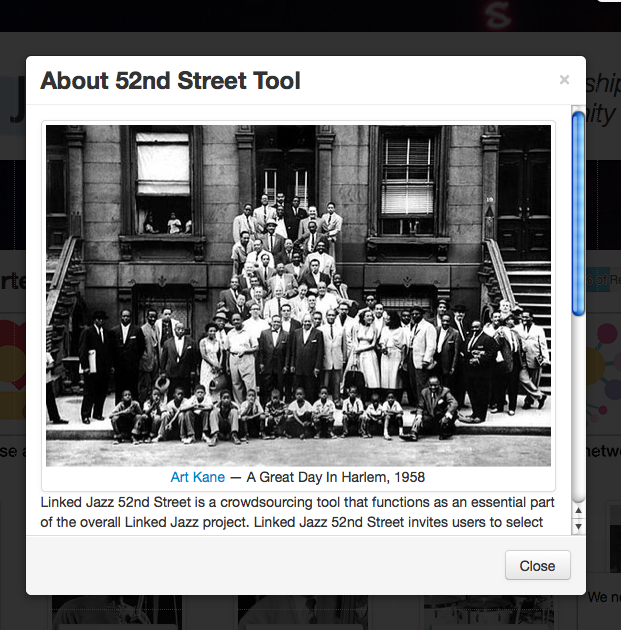
Figure 4. "About" section on the Linked Jazz 52nd Street landing page
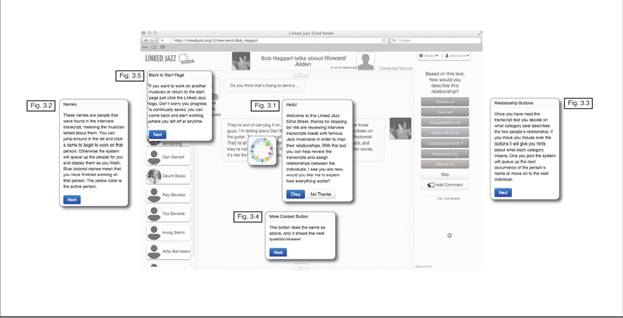
Figure 5. Linked Jazz 52nd Street tutorial
Once users begin working on an interview transcript, methods of sustaining their interest and motivation include:
- A dynamic ego network, which tracks the relationships assigned by the user in real time
- A progress bar showing what percentage of the relationships in a particular transcript the user has completed
In figure 6, a dynamic ego network grows in the bottom right corner of the task interface as the user chooses relationships. A progress bar at the top of the network graphic shows the percentage of relationships that the user has identified and lets the user know where she or he is in the process.
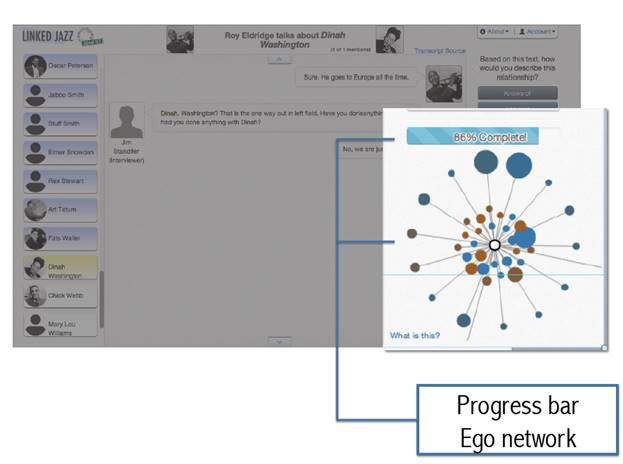
Figure 6. Linked Jazz 52nd Street ego network and progress bar for its growth
To further improve the user-friendliness of this crowdsourcing tool, we engaged Professor Craig MacDonald and a select group of students in his usability class at the Pratt Institute School of Information and Library Science to conduct a usability study on the Linked Jazz 52nd Street tool. Ten individuals participated in the usability study, which consisted of a pre-task questionnaire, three tasks, and a post-task questionnaire. The evaluation criteria were (1) the participant's experience while using the site, (2) the site's design and functionality, and (3) the participant's level of engagement.
The results of the usability testing were mixed. Participants indicated they:
- Had a positive experience overall while using the site.
- Were likely to visit the site again.
- Found the site visually appealing.
- Did not always fully understand their contributions to the larger project.
- Did not become fully engaged with the site while using it.
The Linked Jazz team is taking a number of the recommendations from the usability study into account (alongside online user feedback) to refine the 52nd Street site, such as improving the login mechanism and the user-friendliness of the task interface.
Future Work: Creating More Connections
One vital reason the Linked Jazz project launched successfully was the interest in linked data and increasing access to archival materials among several higher education institutions. The starting point for the project was a connection with the Institute of Jazz Studies at Rutgers University, which houses the papers of jazz great Mary Lou Williams. Co-author Cristina Pattuelli and a small group of her graduate students ran initial experiments on the transcript of interviews of Mary Lou Williams archived at the Institute of Jazz Studies. Since this initial contact, Linked Jazz and the Institute of Jazz Studies have developed a stronger relationship, with Institute of Jazz Studies Archivist Angela Lawrence joining the Linked Jazz team and conversations starting about closer collaborations.
The Linked Jazz team has made connections with several other institutions as well. Columbia University's Center for Jazz Studies recently shared the data they used for J-DISC, an online jazz discography. Linked Jazz team members are now using Python to mash Columbia's discography data with the personal names in our current data set. The team is also collaborating with Tulane University's Hogan Jazz Archive and currently integrating the metadata from their rich collection of digitized photographs of jazz musicians into the Linked Jazz data set.
The long-term goal of the Linked Jazz project is to build a learning resource that uses linked open data to connect the data sets culled from disparate archives and libraries. Our work aims to propose ways to break down the locked silos into which data usually fall, and share some of the lessons learned as we help build an open, shared resource available for the community of linked open data users and developers.
- The Library of Congress Linked Data Service includes the authorities and vocabularies maintained by the Library of Congress. For the Linked Jazz project, we used the Library of Congress Name Authority File.
- A discussion of the use and limitations of DBpedia for personal names can be found in M. Cristina Pattuelli, "Personal name vocabularies as linked open data: A case study of jazz artist names," Journal of Information Science, Vol. 38, No. 6 (2012), pp. 558–565.
- For more details on this stage of the project, see Pattuelli, "Personal name vocabularies," above, and M. Cristina Pattuelli, "FOAF in the Archive: Linking Networks of Information with Networks of People: Final Report to OCLC," 2011 OCLC/ALISE research grant report published electronically by OCLC Research (2012).
- The creation and features of this tool are described in more detail in Matthew Miller, Jeff Walloch, and M. Cristina Pattuelli, "Visualizing Linked Jazz: A web-based tool for social network analysis and exploration," American Society for Information Science and Technology (ASIS&T) Annual Meeting, Baltimore, MD, October 26-30, 2012.
© 2014 Leanora Lange and M. Cristina Pattuelli. The text of this EDUCAUSE Review online article is licensed under the Creative Commons Attribution-NonCommercial 4.0 license.