
Key Takeaways
- Being able to accurately identify, manage, and secure data is imperative in an era where every sector, higher education included, is data-driven.
- The goal of data classification policy is to allow users to understand, better manage, and employ an appropriate level of security for the data.
- Using a risk-based approach, the University of Michigan targeted sensitive regulated data because such data have specific legal and regulatory requirements, as well as fines and penalties for non-compliance.
- Development of a database-driven tool will better explain why specific types of data may be used in specific IT services and under what conditions, as well as provide for a self-service model for users to identify sensitive data and compliant IT systems.
Higher education organizations are typically highly decentralized, which is often reflected in how teaching and research take place — and in the data used for those key educational missions. Being able to accurately identify, manage, and secure data is imperative in an era where every sector, higher education included, is data-driven. The challenge is how to implement an effective policy and toolset that ultimately allows faculty, researchers, staff, and students to identify the data they use and manage it in secure and compliant IT services.
Context of the Problem
Most major research universities engage in the development and publication of IT policies, standards, and related guidance in order to assist faculty, researchers, staff, and students in the proper, secure, and compliant use of institutional IT resources and data. The foundation of any IT policy scheme is a data classification policy that categorizes data by its level of sensitivity. This level of sensitivity, in turn, is driven by privacy and criticality factors, as well as legal and ethical obligations (see U-M web resource on Information Security Laws and Regulations Related to Handling Sensitive Data). The end goal of data classification policy is to allow users to understand and manage data, and employ an appropriate level of security for the data. The ability to have faculty, researchers, staff, and students "help themselves" in this area provides for better data security and compliance in a highly decentralized autonomous environment.
Most university data classification policies assign data into three categories. While the nomenclature may vary, the broad descriptions are typically the same (see Section V. Definitions in the U-M Institutional Data Resource Management Policy):
- Public — data that typically is publicly accessible, requires minimal security controls, and poses little or no risk to the university's reputation, resources, services, or individuals. Note, however, that just because certain data is available under state and federal public records or freedom of information laws does not mean it should be classified as public.
- Confidential — data whose unauthorized disclosure may have moderate adverse effects on a university's reputation, resources, services, or individuals. This is typically the default classification for most organizations and requires a moderate level of security.
- Sensitive — data whose unauthorized disclosure may have serious adverse effects on a university's reputation, resources, services, or individuals. Typically, this includes data protected under federal or state regulations, or data that carries with it proprietary, ethical, or privacy considerations. Sensitive data requires the highest level of security.
While it is relatively easy to establish data classification schemes, there are challenges in having these classification schemes translate into secure and compliant data management practices when sharing or storing sensitive data. Users may be confused about the classification schemes themselves and not know how their data fits in or what IT services (e-mail, file transfer, storage, high-performance computing) meet the security and compliance requirements of their data's classification.
Data Classification at the University of Michigan
Like most Tier 1 research universities, U-M has a data classification policy (in U-M's case, embedded in its Institutional Data Resource Management Policy) and various types of supporting documentation. However, as faculty, researcher, staff, and student demand for clear, robust, up-to-date security and compliance information grew, and more new IT services entered the university "marketplace," merely having the policy and supporting documentation was not sufficient to meet user demand. These use cases range from researchers in the College of Engineering needing clarity on where they could store their export control–regulated research to administrative staff needing simple guidance on how they could internally share Social Security numbers for tax purposes.
The tipping point came as U-M began an IT rationalization project that seeks to leverage economies of scale by consolidating centrally provided, enterprise commodity services (storage, e-mail, database management, collaboration) and/or leveraging external service providers to replace similar campus unit-level IT functions. As a result, users would no longer look to their local college or department IT unit for compliant and secure services. To facilitate this shift in IT service responsibility, it became imperative to develop a simple, easy-to-use tool to assist users in understanding their data and guide them to IT services that meet their security and compliance needs.
U-M Approach
To meet this immediate need, U-M developed a Sensitive Regulated Data: Permitted and Restricted Uses Standard.1 Using a risk-based approach, the university specifically targeted sensitive regulated data because such data have specific legal and regulatory requirements (breach notice, privacy and security safeguards, geographic or nationality restrictions), as well as penalties for compliance failures (see U-M web resource on Information Security Laws and Regulations Related to Handling Sensitive Data).
This standard defines permitted and restricted uses of sensitive regulated data, including the IT environments in which the data is maintained by university faculty, researchers, and staff. The user actionable information is found in the tables that identify data types and the IT services in which they are permitted (see sample table 1).
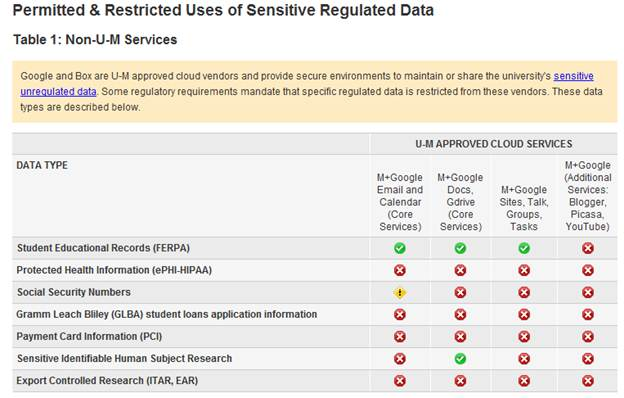
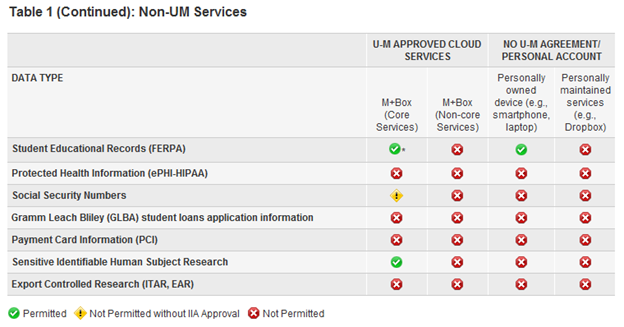
The tables were developed by a core team of Information and Technology Services (ITS) IT security, compliance, and privacy experts over the course of 6–8 weeks. The tables were then reviewed and validated by relevant university IT service owners, data stewards, the office of the general counsel, and the U-M Health System Compliance office. ITS remains the owner of the standard from a governance perspective.
The standard and tables were published in January 2012 to coincide with U-M beginning its Google Apps for Education (M+Google) rollout. Publication of the standard was vital to this effort because the move to M+Google necessitated changes in compliance-related data management practice (for example, College of Engineering faculty and researchers could no longer use e-mail to share export control–regulated research).
Since the standard and tables were published in January 2012 (to time with the U-M beginning to roll out M+Google), the table has been periodically updated and modified. Over the course of 2012, the number of separate tables has doubled in size to account for new services. The updates and modifications have typically reflected the addition of a new, university-wide service offering (e.g. M+Box was not in the first iteration of the tables) but also account for faculty, researcher, and staff input.
At the time of this writing, ITS web developers are working on a new data-use web tool that will replace the tables found in the Sensitive Regulated Data: Permitted and Restricted Uses Standard. This database-driven tool will provide more extensive guidance to users, explaining why specific data may be used in specific services and under what conditions (replacing the simple "stoplight" look of the tables).
The new tool will:
- Allow users to search for information about secure and compliant IT services, data type, or the service itself, as well as pull together all of this information based on their role.
- Provide more explicit, specific, and rich information to the user then the current iteration of the Sensitive Regulated Data: Permitted and Restricted Uses Standard.
- Act as a self-service method for classifying data and answering questions related to compliant IT systems. This in turn will reduce current staff time spent responding to user inquiries.
The new data-use web tool is scheduled to go live by February 2013. The current draft landing page for this new web tool appears in figure 1.
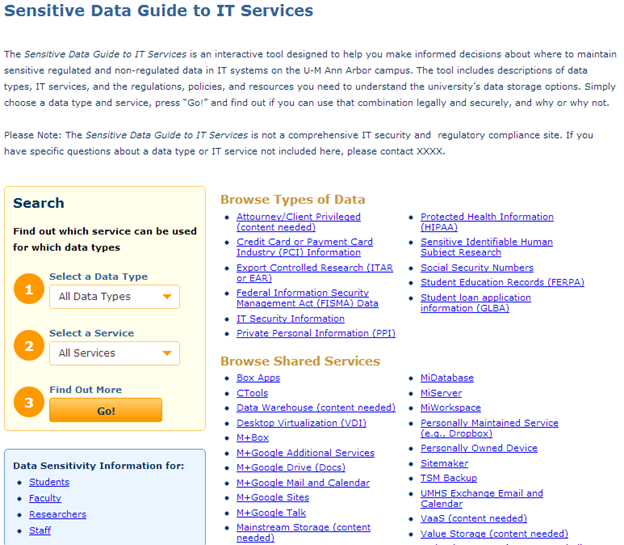
Figure 1. Draft landing page for the U-M data-use web tool (fall 2012)
U-M Challenges
ITS encountered a number of challenges as it developed the Sensitive Regulated Data: Permitted and Restricted Uses Standard.
The first challenge was on which types of data to focus. For the initial publication of the standard, the data was limited to specific sensitive regulated types; as previously noted, this data was selected based on legal and regulatory requirements, as well as penalties for compliance failures. This allowed the university to focus on the highest-risk data and build specific regulatory requirements (e.g. export–control regulatory requirements related to IT staff nationality, HIPAA administrative, technical, and physical safeguards) into specific service offerings (see table 2).
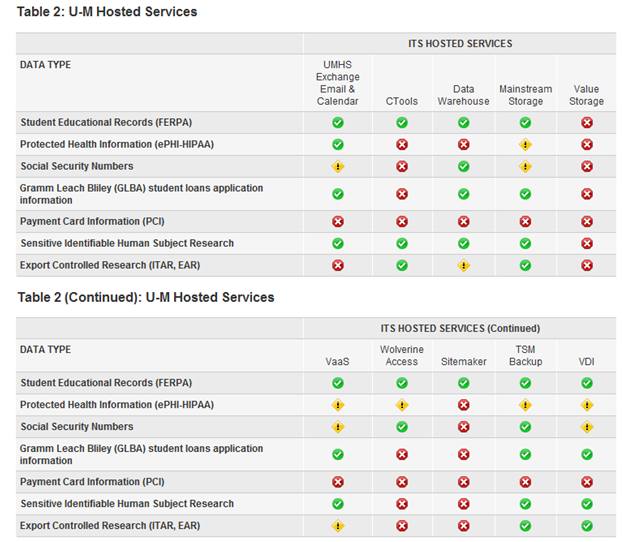
The second challenge was in selecting the types of regulations. ITS selected the data regulations based on commonality across units and the health system, and those that impacted the greatest number of users, recognizing that not all regulations might be taken into account. These edge cases are addressed on an individual basis by ITS and the unit with the edge case need.
A third challenge was how to scale the tables in the standard to include ever-expanding and -changing services. ITS recognized from the beginning that the tables were neither optimal nor sustainable as a tool. For this reason, work began on the next-generation data-use web tool soon after the standard was published.
The fourth challenge was how to proactively and retroactively review service offerings, with particular attention being paid to baking security and compliance reviews into the development life cycle and procurement processes (e.g. engaging in service provider security and compliance reviews before rolling out new services like M+Google) . Over the past year, ITS has developed tools and processes, including a standard service provider security and compliance questionnaire based on the Cloud Security Alliance Consensus Assessments Initiative Questionnaire to meet this challenge.2
This U-M questionnaire is being integrated into the overall university procurement and vendor review process. It has been used in assessing services ranging from e-textbook providers to hard-drive back-up services to travel agent partnerships. The result of a consistent university approach to assessing vendor security and compliance risk is that the university is better positioned to build additional security and compliance assurances into the vendor contracts and/or make stronger risk-based decisions when selecting a vendor.
The final challenge was how to get users to adopt the tool. Because publication of the standard was tied to U-M's M+Google implementation, it brought a high level of university-wide and individual user visibility. Therefore, U-M did not need to have a separate education campaign for the standard and its tables, and ongoing awareness of the standard has been relatively high. ITS anticipates a broader education and awareness campaign for the next-generation data-use web tool once it is ready to go live, and ITS Communications is in the preliminary planning stages for this effort.
Conclusion
Providing users the means to accurately identify, manage, and secure data is imperative in an era of data-driven institutions. Because the number of IT services is growing continuously, providing users with the ability to help themselves is crucial to enabling stakeholders to meet their institutional, legal, and compliance requirements and to avoid overloading IT support staff.
Having a simple, static data classification policy is not enough. Providing users with static examples of data types and the IT services that align with these services (see the tables found in the Sensitive Regulated Data: Permitted and Restricted Uses Standard) is a step forward, but it is not sustainable due to myriad types of sensitive data and an ever-expanding suite of IT services that use the data. The University of Michigan's development of a database-driven tool will provide expanded guidance to users, explaining why specific data may be used in specific IT services and under what conditions, as well as a self-service model for users to identify sensitive data and compliant IT systems.
- Note that sensitive regulated data is not a formal data classification, but is simply a subset of sensitive data.
- Assessment of the questionnaire is performed by ITS security and compliance experts, with the results becoming part of the overall vendor review package.
© 2013 Sol Berman. The text of this EDUCAUSE Review Online article is licensed under the Creative Commons Attribution-NonCommercial 3.0 license.