

© 2009 Michael L. Nelson. The text of this article is licensed under the Creative Commons Attribution-Share Alike 3.0 License (http://creativecommons.org/licenses/by-sa/3.0/).
EDUCAUSE Review, vol. 44, no. 4 (July/August 2009): 6–7
When invited to participate in the NSF/JISC Repositories Workshop in April 2007 (http://www.sis.pitt.edu/~repwkshop/), I was tasked to consider if "data-driven science is becoming a new scientific paradigm — ranking with theory, experimentation, and computational science." I considered the question carefully. Ultimately, I arrived at the old adage concerning the difference between ignorance and apathy: I don't know and I don't care.
Data-driven science may in fact be a legitimate, new, fourth scientific paradigm. Or it could be an extension to and radical transformation of the existing paradigms of theory, experimentation, and computation. Classifying the impact of the vast quantities of data on the scientific process makes for an interesting epistemological exercise, but in practice, I suspect it just doesn't matter. The reality is that science is becoming data-driven at a scale previously unimagined. The ubiquity of access and the volume of data will fundamentally transform the scientific process.
Rudolphine Tables
Data-driven science is not necessarily new: a compelling argument can be made that the astronomer Tycho Brahe and his assistant Johannes Kepler were doing data-driven science, at least by the scale of their time. Kepler published the Rudolphine Tables in 1627, some twenty-six years after Brahe's death. The tables were a catalog of stars and planets and were largely based on Brahe's observations, which were considered to be the most accurate and detailed of the time. The Rudolphine Tables formed the core of the data that Kepler used to derive his laws of planetary motion. That the Rudolphine Tables were published at all is amazing: significant infrastructure costs (in the form of purpose-built observatories), professional jealousies, intellectual property restrictions, and political and religious instabilities dominate this story. The cost, the scale, and the legal and social concerns involved in the story of the Rudolphine Tables make it the Google Book project of the seventeenth century.
What Drives Advancement?
I spent the first eleven years of my career at NASA Langley Research Center. As a computer scientist at an aerospace research center, I managed to learn only two important things concerning aeronautics: (1) "the pointy end goes first,"1 and (2) the somewhat counterintuitive idea that advances in "air frames" (what you and I call "aircraft") are largely driven by advances in "propulsion systems" (what you and I call "engines"). My understanding is that aircraft evolve to a point where engines are the limiting factor. It is not until the engines become appreciably more efficient/powerful/compact than previous engines that the entire aircraft and its deployment profile can advance.
Data is the engine that drives all scientific paradigms. The scientific paradigms can be differentiated by the amount of data they produce and consume:
- Theory: The primary scientific paradigm, requiring little in the way of resources or data to construct models
- Experimentation: The use of apparatus, artifacts, and observation to test theories and construct models
- Computation: Arguably a specialization of experimentation, with the tools focused around the unique opportunities provided by numerical techniques afforded by computers
At each level, increasing amounts of data are required. It could be argued that more data makes each successive level possible (e.g., from theory to experimentation), or it could be argued that a significant-enough change in the volume and kind of data warrants its own description (e.g., computation can be seen as a form of experimentation). The existence of volumes of data alone does not constitute science, and although I cannot imagine a use of data that does not fit into one of the three categories, that does not mean that a new use does not exist.
Challenges
Rather than debate the classification of this phenomenon, I think it is more profitable to focus on the challenges presented by this new scale of data-driven science.
The definition and the dynamics of the scientific artifact are changing. The scholarly communication process is optimized for information artifacts of a certain size and description. Books, journals, proceedings, and reports have a self-contained nature that facilitates publishing, distribution, and long-term preservation. The Rudolphine Tables may have been an early example of data-driven science, but observations of some 1,000 objects were easily expressible in book form. Software, data sets, multimedia, and the like do not neatly fit into the existing practices and are treated as second-class artifacts.2 Books with long-missing CD-ROMs, papers riddled with "404" URLs, and quaint phrases like "contact the authors for the complete data set" capture the difficulty that the current processes have with the increasing volume and types of data supporting their endeavor. While the scientific process is becoming more data-driven, the scholarly communication process, even though largely automated, continues much as it has for hundreds of years.3 We must account for the increasing amount of scientific data and associated artifacts that go uncollected by the current communication process.
Information may want to be free, but data is not as driven. In fact, data is pretty much a slacker: it might have a lot of potential, but it's not going anywhere unless you stay on top of it. As the type and the scale of the data increase, the difficulty in preserving and understanding it also increases: data sets masquerading as books and source code frozen in appendices of journals are insufficient to support data-driven science as it is today. In the Archive Ingest and Handling Test (http://www.digitalpreservation.gov/partners/aiht/aiht.html), sponsored by the Library of Congress, I was part of one of four teams tasked with "preserving" a medium-sized website and with exchanging our archive with another project participant after one year. The sobering reality was that once the website had been processed for "archiving," the exchange of the content was very difficult and required significant manual intervention, despite the level of coordination between project members, the short duration of the project, and the fact that three of the four participants used the same XML encoding scheme (Metadata Encoding and Transmission Standard, or METS).
One of the lessons I learned from the Archive Ingest and Handling Test was that digital preservation is the software engineering problem writ large. Unsurprisingly, digital preservation as a nascent field has been dominated by the adaptation of traditional archiving practices. I believe the field would do well to embrace the software engineering discipline (or perhaps, to go in the other direction, software engineers should be encouraged to take a longer view of time and cast their research as preservation). The division between code and data is somewhat artificial (not unlike the "data vs. metadata" distinction made in web-based information retrieval), and to focus solely on one without the other is myopic.
Who will capture this data, and where will it live? Not only are the nature and the size of the science artifacts changing, but the manner in which they are acquired and stored is changing too. Figure 1 shows an approximation of the cost functions required to acquire and curate scientific artifacts with different data dependencies. The blue line represents the cost of the theoretical model: small initial costs; small runout costs. The red line represents the experimental model: high initial costs; small runout costs. The green line represents the computational model: moderate initial costs; slightly higher runout costs. The black line represents the data-driven model: some initial costs; nearly flat runout costs.
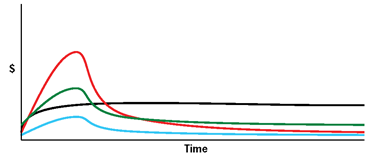
Figure 1: Cost Functions for Theoretical (blue), Experimental (red), Computational (green), and Data-Driven (black) Models
The runout costs include not just the costs of maintaining the repositories but also the costs of acquisition and long-term preservation: refreshing, migrating to new formats, supporting continued access, tracking changes, verifying provenance — all the tasks that are currently handled in small scale by the book and journal publisher/library arrangement. The acquisition component should not be overlooked; there are currently many woefully underfilled institutional repositories (IRs).4 The reasons for the slow accession rates of these IRs are manifold, but improper incentives are probably just as much to blame as a lack of technology.
Summary
I don't know or care if data-driven science is a new paradigm. What I do care about is the data itself: where it will come from and how it will be stored and preserved. Web-scale collections of data will drive new innovations in science. Perhaps all science wants to be data-driven but could not be, until now. Despite our familiarity with the aphorism "information wants to be free," the story of Brahe, Kepler, and the Rudolphine Tables reminds us that freedom occurs only after a great deal of work, complexity, and expense.
- As it turns out, experimental aircraft such as the "Oblique Flying Wing" <http://www.obliqueflyingwing.com/> invalidate the universality of this lesson. Apparently, I learned only one thing.
- For a more detailed discussion, see Peter Murray-Rust, "Data-Driven Science: A Scientist's View," NSF/JISC Repositories Workshop position paper, April 10, 2007, <http://www.sis.pitt.edu/~repwkshop/papers/murray.html>.
- See "Lifecycles for Information Integration in Distributed Scholarly Communication," Pathways project, <http://www.infosci.cornell.edu/pathways/>.
- For example, see Philip M. Davis and Matthew J. L. Connolly, "Institutional Repositories: Evaluating the Reasons for Non-Use of Cornell University's Installation of DSpace," D-Lib Magazine, vol. 13, no. 3/4 (March/April 2007), <http://www.dlib.org/dlib/march07/davis/03davis.html>, and S. Harnad, "Why Cornell's Institutional Repository Is Near-Empty," University of Southampton Technical Report, 2007, <http://eprints.ecs.soton.ac.uk/13967/>.