
The effective implementation and use of adaptive learning systems requires a broad, more inclusive conversation among institutions, vendors, and other stakeholders to realize the benefits of next-generation personalized learning.

Virtually every academic area that studies various anthropology disciplines has been largely based on the same research method: assemble groups of individuals into an experiment scenario, determine their average response to the conditions, and use the same averaging to extrapolate a general conclusion for all people. Our current didactic, transactional digital learning solutions are designed around the concept of sameness. It's like the lull before a storm: calm and uneventful.
A haboob—an intense dust storm carried on an atmospheric gravity current—can serve as an analogy of why this strategy doesn't work. Haboobs often arrive without warning, and the dust and debris they carry are blinding, making it impossible to see where you're going until after the sediment has settled. People's reactions to the giant wall of dust vary, from fear and a desire to travel as far in the opposite direction of the storm as possible, to a scientific or adventure-seeking fascination and a desire to chase after it.
Similarly, the swirl of talk about the innovations surrounding adaptive learning systems arrived unexpectedly (before many of us were fully aware of the developments) and involved high-level, abstract discussions, making it difficult to see where we are now or where we want to go. And reactions in the higher education community have been varied: some have ignored the new technologies, whereas others have quickly (too quickly?) embraced these learning systems. To clear the air, we need a larger, more inclusive conversation among institutions, vendors, and other stakeholders in order to provide more granular thinking around specific minimally viable requirements for the application of adaptive learning systems.
Calm Before the Storm: What Problems Do Adaptive Systems Hope to Solve?
Intelligent adaptive learning systems are quickly emerging but are still in experimental stages. The intended design of these data-adaptive solutions seeks to enable differentiated instruction at a personalized level of learning. New approaches to diagnostic and formative assessment design making use of adaptive intelligence are becoming more common. Adaptive learning systems are designed to dynamically adjust to the level or type of course content based on an individual student's abilities or skill attainment, in ways that accelerate a learner's performance with both automated and instructor interventions. These adaptive systems achieve this by helping to address learning challenges such as varying student learning ability, diverse student backgrounds, and resource limitations. The intent of these machine learning systems is to use proficiency and determine what a student really knows and to accurately and logically move students through a sequential learning path to prescribed learning outcomes and skill mastery. These specific features will transform first-generation digital learning systems. The advantages include, but are not limited to, the following:
- Automated processes of student assessment and predictive analysis result in significant faculty time efficiencies.
- Adaptive systems have the potential to solve the primary and perennial problem in public education: the overwhelming challenge of teachers or faculty being responsible for accomplishing learning mastery among a demographically diverse set of students.
- Adaptive systems address the fundamentally different levels of prior knowledge, as well as course content progression based on students' skill and outcomes mastery measurement, decreasing faculty load in teaching and remediation to teaching and facilitating.
- Executed effectively, the cost efficiencies in automated feedback and remediation without formal instructor intervention have shown major improvements in student learning.
- Regulating course content degree of difficulty results in better course engagement and progression.
- Students own their learning journey: real-time response to their ongoing coursework provides detailed feedback for self-mediation.
- Adaptive systems encourage student ownership of their learning through automated feedback cycles prompting them to take action and advance independently of the class instructor.
- Adaptive systems conform to individual students' varied lifestyles versus students having to conform to the system.
- Faculty receive data with insights into individual students' needs. Adaptive systems can provide a level of automation allowing faculty to better allocate time to students who need remediation.
- The technology actively uses research about how people learn. Correctly developed, adaptive systems reveal how individual students learn.
- Adaptive systems empower faculty. Rich data analysis of student progression enables faculty to continually improve course design.
- Traditional assessment methods inform both faculty and students too late in the learning cycle. Using timely and comprehensive data-driven feedback, adaptive systems can inform in real time.
Adaptive systems have the potential to shift education in the service of students by providing a student-centric design. The student-centered capabilities these systems aspire to provide are vastly unlike the current models for traditional classroom support—models deeply rooted in student administration. The underlying data systems and transaction timing (e.g., gradebook, end-of-course exams) are radically different from the real-time, learner-specific data that forms the foundation of student-centered learning.
No Two Dust Clouds Are Alike: Adaptive Learning Shapes and Sizes
There are many forms of adaptive learning systems. While classifications in other industries are narrower in defining their specific applications and use cases, there are no specific guidelines, taxonomies, or common vernacular for how various types of adaptive capabilities are described in the edtech industry. These new data-driven systems are expansive in categorical descriptions and desperately need more specifics to describe and evaluate appropriateness for any given instructional design and teaching and learning purpose. Key tenants of these first-generation adaptive systems include the following:
- Automation: The ability to create automated processes that reduce more manual teaching processes in assessment, evaluation, remediation, and competency attainment
- Sequencing: The ability to create a sequenced progression of skills and competencies contained in a finite learning path in a term or non-term unit of time
- Assessment: The ability to employ combinations of benchmark, diagnostic, and formative assessments on a more immediate and continuous evaluation
- Real-time data collection: The ability to collect, calculate, and evaluate data, from an array of sources, with some assumed inference method in real or near-real time
- Self-organizing: The ability to self-organize information and data results from inferences to form ongoing and persistent feedback in the teaching and learning cycle
With these commonalities in mind, we have identified four types and variants of adaptive learning systems: machine-learning-based adaptive systems; advanced algorithm adaptive systems; rules-based adaptive systems; and decision-tree adaptive systems.
Machine-Learning-Based Adaptive Systems
Machine-learning-based adaptive platforms are the most sophisticated scientific method in which to establish a truly adaptive state. Machine learning (ML) is synonymous with pattern recognition, statistical modeling, predictive analytics, statistical regularities, and other forms of advanced adaptive capabilities. ML-based systems use programmed algorithms to create the adaptive science core and make real-time predictions about a learner's subject matter mastery. ML-based adaptive platforms use learning algorithms, known also as "learners," to create other algorithms, which in turn create adaptive sequences and predictive analytics that can continuously collect data and use it to move a student through a guided learning path. These ML learners continually harvest data in real time, determining students' proficiency in mastering objective-specific content modules. The data is then used to automatically adjust the overall sequence of skills or the type of content a student experiences. Learning algorithms create analytical models that are designed to produce reliable, repeatable decisions, and results reveal undiscovered insights in student mastery through ongoing evaluation of historical relationships and trends in the data.
What's unique about ML-based adaptive systems is their ability to detect how an individual learns and approaches a learning task as part of these intelligent systems, as well as provide accurate and timely feedback and improve student performance. Since ML-based systems are highly computational, analyzing billions of data bits in real time, system scalability can be a question from two perspectives: how these systems are efficiently coded; and the provisioning architecture used to process, load, and balance enormous amounts of data. At minimum, ML systems feature the following:
- Continuous and dynamic improvement: The instructional method improves over time.
- Learner profiles: A baseline profile is used to classify learners' characteristics, such as demographic information, learning style attributes, academic strengths and weaknesses, and learning preferences.
- Personal path and pacing: Learners can automate the process of self-instructional pacing for any particular individualized learning path or time sequence that is predetermined.
- Individualized feedback and remediation: The system has the capacity to infer an individual student's knowledge level and accurately provides general feedback and remediation activity based on collective performance knowledge.
- Content-agnostic: The system assumes relative knowledge of student mastery based on a variety of learning mediums such as text, video, audio, and other content.
Advanced Algorithm Adaptive Systems
Advanced algorithm (AA) adaptive systems provide 1:1 computer-to-student interaction, making it scalable based on the type of content (usually mathematics and sciences). Content modules are prescribed to specific, individual learner profiles based on prior proven mastery of knowledge and applied knowledge activity. In AA systems, learning paths, feedback, and content are evaluated in real time by constantly analyzing data from the individual student and comparing it with data from other students exposed to the same or similar content. AA adaptive systems record and manage a large amount of data, tied to a learner profile, and record clickstreams, time intervals, assessment attempts, and other transactional behavioral data. In AA systems, learning paths are determined in real time, and feedback is provided instantly in response to the data analytics running in the background. Instructional methods and content are altered where certain predetermined learning paths are ineffective, and alternative content, feedback, or remediation is provided.
Rules-Based Adaptive Systems
Rules-based (RB) adaptive systems work on a preconceived set of rules and do not precisely adapt to an individual learner, using ML-like scientific methods. RB is not designed around an algorithmic approach; rather, the particular learning path in these systems is predetermined by rule sets that can change for individual learners, and feedback is provided once a learning unit is concluded. In a self-paced learner use case, the student's learning path is usually sequential and linear, with little-to-no personalized adaptation other than a predetermined set of conditions. Students may take a differentiated path through assessment of prior knowledge and can progress individually at their own pace. RB systems don't use learner profile information and learning characteristics. Students go through a predetermined learning path with predetermined assignment sequences but can, depending on persistent diagnostic assessments, advance or regress individually. Ongoing feedback is provided, and remediation is prescribed based on the predetermined set of rules. RB systems use a smaller, more contrived set of content, matching diagnostic and formative assessment rules with the next sequences of content. The instructional method is not improved as learners progress through a path unless the content sequence is manually altered.
Decision Tree Adaptive Systems
Decision tree (DT) adaptive systems are a relatively simple classification designed around the concept of a "tree" of prescribed and limited repositories of content, assessments, and answer banks. Usually DT systems have limited assessment item types that are binary in their form and function. DT is differentiated from RB in that the rules and associated learning materials are relatively static and do not change. DT systems don't take into consideration a specific learner profile but use a series of static "if this, then that" (IFTT) branching sequences. DT systems, depending on their design sophistication, can take the form of intelligent recommending systems but are not knowledge-based in that there is no inherent collective and historical knowledge capture. However, these systems can infer a learning path from case-based reasoning using basic IFTT logic that supports users in the learning process by the selection of an individual learning path interacting with an inventory of didactic learning content. DT systems use an established set of rules from a pre-prescribed set of content modules and pre-prescribed sets of assessments and answer banks. Using intervals of data and feedback, learner workflows are created and individualized work streams assigned throughout a set pace.
Seeding the Storm: Adaptive Learning Systems Requirements
There is increasing market ambiguity and growing concern about the "black box" of personalized learning. What is the real anatomy of the next promising personalized learning environment? As more market capital is being used to fuel and accelerate the development of adaptive learning systems by the private sector, higher education research must set the foundation for the key design requirements necessary for these next-generation systems to reach their full potential and meet their rhetorical promises. Adaptive learning systems require, at the core, an architecture that integrates key functions of modular content, assessment, and competency mapping that work together to support a personalized learning ecosystem.
At minimum, adaptive systems are composed of methods that organize modular content to be learned, multiple systems of assessment that track and evaluate students' abilities, and techniques of matching the presentation of content to individual learners in dynamic and personalized ways. Based on close observation of the work in which we are currently engaged in adaptive learning systems experimentation, we have constructed the following framework for a minimally viable product design—or what should be inside the black box. In the outline of core requirements, the three integrated and interdependent areas of content, assessment, and competency frameworks are essential in creating true adaptive states.
Content
- Content Scaffolding: Content modules are designed to index critical concepts, which present a multistep problem as a series of smaller problems used to help students synthesize concepts when those concepts are still new to them. Scaffolding is especially relevant in adaptive systems where students need to apply their knowledge to new scenarios learned. Scaffolding methods are designed to statistically provide different follow-up questions to various students, depending on their level of proficiency. Content scaffolding allows students to apply the original learned concept to a variety of analogous situations.
- Social Interaction: Social connectedness within an adaptive course is a key element in the multiple measures of both cognition and engagement. In the adaptive field, content-driven group collaboration extends the functionality of student mastery measurement. Personalized learning can and should be incorporated to facilitate collaboration between learning teams and forums, as well as resource-sharing capabilities. While no current systems have integrated synchronous capabilities, adaptive systems can be a key foundation to link personalization of customized content to students' profiles and interests, automated grouping of users with parallel interests, and even peer-ranking indexes.
- Content Interoperability: Adaptive systems need to take into consideration content management and interoperability requirements. Interoperable content models need to have built-in methods by which specific topics or content domains are structured with aligned learning outcomes and learning task definitions. Adaptive systems need to be capable of configuring predetermined content sequencing as well as variable sequencing tied to ongoing measurements of skill mastery. They need to have interoperable content management systems in order to identify content appropriateness based on what the system knows about what the student knows in an ongoing and dynamic way.
- Metadata: Equally important is the built-in capability of developing key identifiers linking content to other content where there are concept interrelationships and adjacencies. Simply defined, metadata is data that describes information about other data—a method for advanced tagging of content with underlying data about each module of content (e.g., subject area identifiers, age and level, learning outcome). All adaptive systems, no matter their level of sophistication, must have a defined, advanced metadata schema in order to achieve a personalized state.
Assessment
- Normed- vs. Criterion-Referenced Assessments: Normed-reference (NR) assessments are designed to compare individual students' achievement to that of a "norm group," or a representative sample of peers in the same or similar cohort group. NR assessments do not compare the students' achievements tied to a particular set of standards or defined outcomes for what students actually should know and be able to do; they only compare students to other students in the same norm group. In NR, learners do not address questions that refer to a particular skill and demonstrated knowledge. NR tests make it mathematically impossible for all the children to be above average. Conversely, criterion-referenced (CR) assessments are designed to show how students achieve as directly referenced to a set of standards or defined outcomes. CR assessments are specifically designed to determine whether students have mastered the knowledge and skills contained in the defined set of outcomes. CR tests begin with the outcome in mind: the knowledge and skills students are expected to learn and be able to apply. Most adaptive systems in the market today use only an NR assessment process, which is the key component in determining adaptive content placement. It is merely a mathematical computation and requires a significant number of student participants in order to be statistically accurate.
- Predictive Psychometric Design: Truly designed adaptive tests have the ability to achieve accurate placement of a student in an individualized learning path. Predictive capabilities are derived from adaptive assessment design whereby each test question can be altered by the response to the previous question, and the test rigor is variable. Adaptive assessment must use a stable scale, which is the only way to accurately show a student's growth over time, regardless of grade-level performance. There must be built-in predictive values using mechanisms that automate the selection of questions based on the student's responses and reports that relate scores to the student's instructional needs.
- Diagnostic Classification Modeling: Diagnostic classification models determine learner mastery or nonmastery of a set of attributes or skills. These assessment models are used to diagnose cognition, particular skill competency, or subcompetency of a defined outcome. Diagnostic models are particularly important in adaptive systems because they are used to align teaching, learning, and assessment—and to give timely diagnostic feedback by knowing students' weaknesses and strengths to guide teaching and learning in the adaptive processes.
- Zone of Proximal Development: By definition, zone of proximal development (ZPD) is the difference between what learners can do without help and what they can do with help. ZPD is used to serve content within learners' "zones" to establish an appropriate adaptive baseline. ZPD is particularly useful to measure what students are able to master within a social setting. Using ZPD methods enables the sequential movement of skill mastery on an individual student-to-student basis. It also allows adaptive systems to measure and provide next-step guidance and feedback. ZPD is an important element in content scaffolding, where a learning aid can be applied when necessary within a personalized learning experience.
- Self-Assessment: In any adaptive system, it is important to measure learners' interpretation of what they know versus what they actually know as measured by the adaptivity. Self-assessment capability provides adaptive systems with benchmarks on how students monitor and evaluate the quality of their learning behavior when learning and identifying strategies that improve their understanding and skills in automated ways. It compares students' judgment about their own work versus what the adaptive systems know about the sequential work that has been completed at any given learning interval.
Competency Frameworks
- Skill Standards Libraries: Competencies are defined units of knowledge, skills, and abilities used to evaluate skill mastery and the demonstrated application of those skills. Core competencies serve as standards of practice for program mastery in K-16 education, as well as for workforce competency definitions. Modular adaptive content and assessment need to be built on the foundation of these broad skill standards libraries and act as a correlative "reference point" or outcome based on a framework across a number of subject and skill area domains. Each competency and skill definition focuses on the performance of the end product or goal state of instruction and reflects mastery expectations external to the instructional program. These skill standards libraries judge competence through the use of a standard that is not dependent on the performance of other learners, and standards libraries inform learners, as well as other stakeholders, about what is expected of them. Competency and skill definitions must be comprehensive in ways that confirm mastery in a learner's ability to source, process, manage, communicate, and apply knowledge across diverse contexts seen as critical for successful K-16 programs and workplace success.
- Parent/Child Relationships and Competencies/Sub-Competencies: In any given competency framework, identified skills and competencies are further defined by a subset of competencies and skills, or "sub-competencies." They are specific facets of an individual, aggregate competency. Sub-competencies are a broad array of constituent "nested" elements that make up a complete competency structure linked together into parent-child relationships. Learners progress through mastery of a series of sub-competencies accretive to an overall competency that is a key indicator of future success.
- Prerequisite Knowledge and Prior Knowledge Qualifiers: Assessment of prior learning capabilities sets a baseline of established student knowledge, skills, and competences against a predetermined standard. Prior learning assessments are learner-centered; they validate learning and give credit for what learners already know, placing learners at a starting point for the next viable competency to be learned in order to move forward and build on existing knowledge. Assessing broad ranges of prior knowledge before entering an adaptive course has a direct impact on student engagement as it shortcuts the course-pacing process. Adaptive systems are engineered to account for new knowledge becoming prior knowledge to be used as a building block for further knowledge and competency attainment.
Ultimately, adaptive learning systems will need to develop and embrace some degree of standards, taxonomy, and minimally viable product definitions in order to create order out of the current chaos. Not creating and adopting a more rigid framework will leave the market open to continued ambiguity. Figure 1 shows a conceptual model of minimal viable product (MVP) of truly adaptive system design.
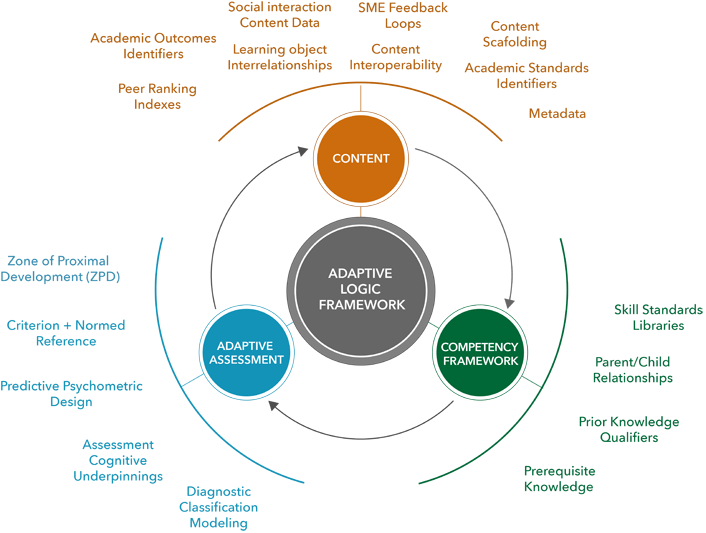
Figure 1. Adaptive Logic Model
Source: The Action Lab, EdPlus, Arizona State University
The Initial Gust of Dust: The Adaptive Learning Systems Market
The realization that K-16 education is still at formative stages in the development of fully adaptive systems, as well as the current design of even the most sophisticated systems, leaves gaping holes in the key design requirements that will enable these systems to reach market scale. If these holes are left unaddressed, early adopters who drive market decisions will be largely unsuccessful in developing personalized learning programs for the mainstream market. Failure to execute at scale and with the promised level of achievement will be particularly disruptive to the potential of personalized learning, especially in institutions seeking to transition from a static, one-size-fits-all LMS "transmission model" of education. Gaps we see include, but are not limited to, the following:
- One-off applications: There are currently few adaptive systems with even rudimentary content-authoring tools. Most of these systems are one-off build platforms controlled by the vendor, who provides authoring and adaptive course development services. This removes faculty from the teaching and learning process, relegating them to a sideline approval role.
- Complex design: Adaptive systems are not designed to adapt to the skill level of the teachers and faculty.
- Current behavioral measurement: Adaptive systems lack the measurement and discourse analysis of synchronous communities of online learners engaged in group activity and assignments.
- Integration: Current systems lack integration to disparate applications that can act as valuable inputs to adaptive measurement.
- Voids in instructional design: Current systems lack the flexibility to achieve multiple methods of instructional design to reach a desired result in digital learning.
- Learner profiling: Most adaptive systems do not have robust learner profiling capabilities, especially for a broad base of learner profiles and demographics.
- Synchronous learning: No adaptive systems currently in the market have peer-to-peer learning tools. This misses a valuable and critical knowledge and engagement measurement that factors into the matrix of adaptation. Current systems consider only static content modules and not peer involvement, group knowledge, and/or any other web source of information.
- Content management: Content modules and associated metadata are valuable assets for reuse and reconstitution of adaptive course variations. Most adaptive systems don't have capabilities designed for reusable content in adaptive environments and are not well designed for adding, modifying, and re-creating content.
- Algorithm design: Current adaptive systems are designed for and work best in finite subject areas, such as mathematics. Algorithms and cognitive models should be broad enough to teach the sciences, language arts, humanities, and language acquisition.
- Opaque cognitive modeling: These environments utilize cognitive modeling processes to provide feedback to the student while assessing the student's abilities and adapting the curriculum based on the student's past performance. These processes are unclear, largely unproven, and not research-based. Vendors are often not forthcoming about the science they use to develop and prove cognitive models.
Ten Questions to Ask an Adaptive Learning Systems Vendor
Various companies have taken a first creative shot at developing and designing adaptive systems for what they believe the market requires—not necessarily what the market may need. As a result, it's worth asking any adaptive systems vendor the following ten questions.
Does your adaptive learning system have …
- The ability to adapt and conform to a nontraditional learner lifestyle, where the pace is variable and the learner has on-demand requirements?
- Statistically accurate cognitive models representing authenticity of skill and competency mastery? If so, how does the system achieve that adaptive state?
- Accurate content path placement that includes an assessment of learned knowledge that can be applied?
- The ability to correctly perform adaptive sequencing to precisely and continuously collect real-time data on a student's performance and use it to automatically change a student's learning experience?
- The ability to accurately determine remediation and corrective action using adaptive assessments in both normed- and criterion-referenced assessment design where applicable?
- The correct algorithm design for weighing different multiple-measurement factors? Can you describe how the adaptive logic works in your system?
- Adaptive assessments in the design? Or are assessments derived from traditional formative assessment item banks?
- Synchronous capabilities as a critical measurement of student engagement behavior, as well as content knowledge mastery?
- The necessary provisioning architecture to scale thousands of concurrent users when considering the complex calculations needed to accommodate adaptive learning?
- The ability to develop comprehensive competency frameworks that index learning standards and outcomes?
Surviving the Storm: Barriers to Adoption
It's one challenge to develop adaptive technology capabilities, but it's another challenge to use and actually apply data from adaptive learning systems to teaching. Key stakeholders need to develop a thorough understanding of the intersections among next-generation digital platforms, adaptive pedagogy, and rapid advances in the learning sciences. The most consequential barrier to the adoption of adaptive learning systems is that scientific, multidimensional data methods to effectively facilitate individualized learning and true personalization have only recently begun to emerge. The learning science is not well understood, leaving academic outcome benefits up for conjecture.
Research is expensive, and in the development of private-sector companies, early-stage funding is used to develop market prototypes and version 1.0 commercial-release software, not research. The successful design of these complex adaptive learning systems requires years of research and development and market testing. For K-16 institutions, there is a high cost involved in adopting these systems due to the arduous process of converting existing course content into the adaptive, modular designs required to match the needs and interests of individual learners.
Another challenge is teacher/faculty proficiency in successful adoption and use of adaptive systems implementation. Individualized student learning paths, at variable pace, are advantageous because they allow teaching and remediation to apply to those students with the most need. However, faculty are accustomed to all students in the same online course progressing at the same pace. Altering an instructional strategy to these new capabilities requires significant periods of trial and error.
Next-generation adaptive systems are data-intensive. They need rich amounts of data—about user actions, behavior information, and content interaction—to perform an adequate job of mapping an optimal learning path for students. For personalized learning to realize its full potential in using comprehensive, multidimensional data, systems require access to a wide variety of additional applications in the institutional enterprise data repositories, as well as in third-party web services applications. Most adaptive systems focus solely on data derived from functionality inside the proprietary vendor software application.
"Smart" content repositories require a sufficient amount of metadata generated by some combination of both computers and humans. Metadata, however, also presents challenges and questions: the amount required; the source of the metadata; and the person/department responsible for creating and maintaining rich metadata libraries. If metadata tagging is crowdsourced and open to any participant, it introduces a significant margin for error. In addition, tags need to be maintained and tested for accuracy, corrected, and updated. If the metadata foundation is weak, the entire intent of personalization is compromised.
Lastly, the financial resources required for the initial design or implementation of adaptive learning models and the integration into existing online programs may create a significant barrier to adoption. Since adaptive learning systems are an emerging next-generation technology, few institutions have the financial resources required for investing in the technology infrastructure, software, and licensing fees. Institutions will also need to provide faculty training to effectively design and implement a personalized approach to online instruction.
After the Dust Settles
Many education leaders believe that personalized learning has unprecedented potential to reshape the landscape of how we teach and learn online. Yet higher education faces a shortage of agreed-upon scalable and repeatable methods against which to measure learning and assign value to the efficacy of these next-generation technologies. Adaptive learning systems promise to advance these efforts, but they will have little impact without a basis to measure and assess student learning. Together, we need to define a coherent set of expectations, competencies, standards, and frameworks.
Institutions have been slow to adopt personalized learning mainly due to the lack of awareness of what it is, why it is important, and how to successfully incorporate it into course and program design. With an unprecedented opportunity to redefine and transform digital education, what will it take to move this promising innovation forward? In an environment where there is high potential for the private sector to dictate the rules of engagement, those of us in higher education should consider a number of immediate actions that may impact the successful transition of our digital teaching and learning.
Perhaps the most effective way to create public- and private-sector unity would be to form a higher education, next-generation innovation council supported by institutional, federal, and/or private-sector funding. Similar to the University Innovation Alliance, the council could be designed to pool research in learning science in order to devise best practices or a common framework for the underlying data science necessary to establish accurate states of personalized and adaptive precision. A major goal for an innovation council would be to develop clear criteria for an "approved model" designation, which would be essential to ensure designations of quality and usability. Specific criteria would designate a vendor's commitment to certain performance measures, which the innovation council would monitor and report. Through a mix of private- and public-sector funding, institutions could engage in research and development activities whereby evaluations and experiences could be broadly disseminated. The resulting work might be used as an "ISO 9000" best practices approach for minimally viable requirements. The innovation council would rigorously review adaptive learning systems vendors for specific quality and performance benchmarks and would encourage private-sector providers to invest in developing new models and rigorously evaluating their results. The innovation council could also develop and conduct national workshops for administrative and academic IT preparedness of adaptive technology products and services.
In time the innovation council might incubate and eventually evolve into a central nonprofit organization similar to Internet2 or the IMS Global Learning Consortium, in order to take on a more central leadership role on certain functions supporting innovation. This type of independent organization could also leverage public funding by applying for, receiving, and distributing philanthropic funds for public-private partnerships to promote innovation and personalized learning. Independent nonprofits can also serve as advocates for innovation with state policymakers and K-16 institutions by working to spur demand for new models. To address funding shortfalls for the successful adoption of adaptive technology innovation, the innovation council could also work with federal and state funding opportunities for seed adoption grants.
Scaling access and the effective implementation and use of these groundbreaking, next-generation adaptive learning technologies will require broad strategies to address both demand and supply market dynamics. Higher education has a poor historical track record of seeking out, learning, and applying models outside the education sector. We must observe, analyze, evaluate, and replicate applicable models for personalized learning from the private sector, especially since the areas of business intelligence, financial services, healthcare, and government agencies had a head start of more than a decade. Doing so will give us the metaphorical dust mask needed not only to survive but to thrive in the face of the next big storm.
Lou Pugliese is Senior Innovation Fellow and Managing Director at the Arizona State University (ASU) Action Lab.
© 2016 Lou Pugliese
EDUCAUSE Review, October 17, 2016