
Key Takeaways
- Creating a digital record of research preserves the work indefinitely and makes it accessible to other researchers, whether in the same or seemingly unrelated fields for use in both expected and inventive ways.
- As a research organization covering many fields, the Smithsonian Institution has a vast and growing research record with which to contend.
- The Smithsonian is devoting IT resources to develop the SIdora environment, an evolving architecture to help manage its numerous digital objects and make them accessible to researchers around the world.
- Capturing the record of research requires the researchers to begin managing their data as it is created, leaving a legacy of data that can be curated.
Let me begin by asserting that researchers should become directly involved in describing and organizing the information that results from their activities. Getting them to do this often proves challenging — think "herding cats" — especially when it comes to digitization of research data and processes. Creating and managing the digital record of research is no easy task, of course, but has clear benefits. Not only does digitization preserve the research record indefinitely, it makes it easily accessible to other researchers.
Digitization requires assuring the information's fidelity and authenticity at the moment of creation and throughout its useful life, along with creating various access-control policies. Further, research frameworks should support various types of digital media, including (but not limited to) texts, images, video, audio, tabular data sets, gene-sequencing data, 3D images, and geographic information system data sets.
To begin addressing these challenges at the Smithsonian Institution, the Office of the Chief Information Officer (OCIO) hired me to create a research support program in 2010. In 2011 we created the Office of Research Information Services (ORIS), which I direct. ORIS now has primary responsibility for developing and improving research services, including the institute's high-performance computing cluster, and developing and implementing a research data management system.
As our first effort, I designed and launched a pilot project called SIdora [https://oris.si.edu/sidora] that uses the Islandora open-source framework on top of the Flexible Extensible Digital Object Repository Architecture (Fedora) as a starting point, combining "Smithsonian Institution" with "Digital Object Repository Architecture" in an easily pronounceable name. The SIdora project aims to create a practical support environment for managing a complex array of interrelated, trusted, and durable digital objects in a collaborative framework controlled by fine-grained policies. The development team's immediate challenge was to create an architecture to organize information, along with a "starter set" of software tools that provide enough functionality to make life easy for SIdora's early adopters. This article describes that initial architecture, as well as two successful pilot projects that the ORIS plans to generalize in future pilot projects, paving the way for SIdora's continued organic growth and development.
SIdora’s architecture and software are built on widely used standards and open-source packages. The testbed of research projects available for SIdora's development covers most types of research supported at universities, museums, and other research institutions. Indeed, almost all Smithsonian researchers collaborate directly with such institutions around the world. One of the SIdora project’s primary goals is to become a collaborative, open-source software development project that addresses direct research support and data sharing among collaborating research institutions.
The Smithsonian Institution
British scientist James Smithson bequeathed his estate to the United States to found "under the name of the Smithsonian Institution, an establishment for the increase and diffusion of knowledge." Smithsonian researchers create and use all types of collections in their work. Thus, as the institute developed, preservation became the unofficial third principle of its mission; today, the Smithsonian includes 22 libraries, 19 museums, seven research centers, two major archives (and many smaller ones), and a zoo. Research activities — or the support thereof — occur in all of these units.
The observation-based research associated with the sciences is a major part of the institute's activities. Its strengths include environmental sciences, biodiversity, astrophysics, and scientific research associated with conserving physical collections of all kinds. The museums, especially those associated with cultural heritage, host an array of research projects aimed at putting the collections in context; many years of research can go into a museum exhibition or collection development. To date, however, no systematic effort exists to support and sustain the digital information created in such research activities.
SIdora Overview
As the architect for SIdora, I designed the software environment to capture the full output of research projects, including the intellectual context that organizes the digital artifacts created throughout the research process. SIdora provides the workspace in which researchers gather, organize, and describe data during the fieldwork and data-gathering stages. It gives them complete control of the content and lets them use it directly in their analysis and dissemination activities; they can offer access to others as desired. The formal, structured information that results will stand alongside a researcher's publications as the permanent record of that research. From the institutional viewpoint, SIdora provides a complete record of completed research projects that are ready for curation and long-term management.
Although the development team might want SIdora to support retrospective data capture from earlier projects, we focus on capturing new data as it is created. The SIdora project aims to support researchers through the entire lifecycle of their active research projects, leaving curatable data as a legacy. The tool set we are developing to reach that goal focuses completely on the researcher; tools required by professional curators will be added in a later phase.
Guiding Assumptions
The call to make research information sustainable on its own terms is recent; in reality, these calls rarely come with the resources required to make it happen. At the Smithsonian, OCIO managed the provision of compute cycles and software licenses, but did not directly support research or try to manage the digital information that was created in the process.
SIdora development addresses core assumptions about both the research process and curation of digital research information in the future. In focusing on these core assumptions, we intend to launch a pragmatic effort that starts small.
Assumption 1: Researchers need to describe and organize their data so that they can remember what it means after the fact and leave behind a body of information that professionals can curate.
Organizing digital information to be sustained indefinitely — while also making it useful to the original researcher and others who might want to use it in new contexts — requires a knowledgeable person to make explicit sense of it at the time of creation. Only the research team responsible for creating the data in the first place can properly describe it, and, in spite of good intentions, rarely does anyone want to do that work after the project ends.
The idea that the Smithsonian will provide a cadre of curation professionals to do this work for its researchers is also a non-starter. Given limited resources and the hundreds of researchers in dozens of disciplines at the institution, that simply will not happen. Even if the goal were attainable, the researchers would have to spend significant time explaining their research to curators at every step in the process.
Assumption 2: The goal is to capture a record of the research, formally structuring the project's digital assets in a way that captures the thought and context that drove the work.
Left to their own devices, researchers generally develop individual, implicit ways of organizing their information, using cryptic file and directory names, shorthand notes, and (to a great extent) their memories to provide continuing access to the content. All of these methods quickly become untenable when the responsibility for managing the information changes; in terms of making the content discoverable and usable by other researchers, these methods just don't work
Most importantly, to stand alongside — and relate to — publications, the information from these research projects must be formally conveyed, organized, and sustained. Research projects almost always include multiple media files of various types, with each file representing a facet of the project. These files must be made sense of together to represent the project as a whole. Increasingly, any research project (or any part of a project) constitutes a digital source mined for data that can be used in ways not necessarily foreseen by its creators.
The need to provide results that engender reproducible research demands that we do more than just manage the data directly related to particular publications. To truly support reproducible research and leave behind a legacy of usable data, we must capture the information's complete provenance. This includes all of the project data generated and gathered, as well as information about the researchers' motivations and assumptions, the design of experiments and activities, and a formal record of how all of the parts relate to the project as a whole. All this information must be organized in such a way that someone else can understand and access it after the fact.
Assumption 3: Success must be measured by the ability of future users to repurpose the managed data for use by disciplines other than the one it was created to serve.
The reason for managing data in the first place is to make it possible for someone else to discover and use it. A useful distinction exists here between information reuse and repurposing. Reuse implies that someone from the project's research domain will reuse the data for the same or similar purpose. Repurposing managed information implies that someone from a different domain will use the data to infer something new. Climate science and biodiversity studies, for example, need research data presented and sustained in such a way that they can use it over time. Researchers trying to go back in time to infer baseline data never gathered for their fields have found new meaning in data gathered by archaeologists, paleontologists, and even humanities projects.
If repurposing is the minimum goal for data management, more effort must go to describing the data. That is, shared assumptions among members of the same domain must be made explicit, terms must be normalized, and so on.
Assumption 4: Researchers will be adding to a growing network of information that will require the cooperation of memory institutions worldwide to sustain.
The scientific and scholarly record is rapidly becoming a shared network of information, albeit through a casually organized, fragile patchwork of websites. Community-organized databases aggregate contributed data and make it available, while museums, libraries, and archives digitize their collections and make them available through the web. However, true interoperability does not yet exist.
The linked-data effort is making inroads into solving this problem, but remains largely focused on the discovery problem. As yet, no shared standards exist for making content available and maintaining it as a node in a network.
Part of the problem is that memory organizations continue to make their data available as if their collections are isolated; instead, they must begin to see themselves as offering access to information from their corner of a worldwide information network. Each institution has a responsibility to both sustain the content they manage and to offer access to other providers to sustain the network of interrelated information.
Like the web itself, this research information network must operate as a continuous layer that sits on top of the computing infrastructure that delivers it, which is completely abstracted from the software that will use it. Application developers have always established private data management systems as a shortcut to immediate efficiency; this practice poses a major barrier to the required interoperability.
Assumption 5: The key to data management is to provide a research support environment that makes it easy for researchers to actively manage and control their data from the project's start and use the environment for analysis and dissemination activities.
Ultimately, given the previous assumptions, we must assume that the only feasible way to establish digital information management is to create an environment in which data is naturally, formally, and easily managed in every stage of the research process. To make such an effort scalable, researchers must receive an immediate benefit for managing their information — that is, they must be able to smoothly move information into the analysis and dissemination phases, while also capturing new information created in that process.
In addition to giving researchers powerful, more efficient analysis capabilities, this type of integration offers other benefits as well. For example, computer security is an ever-growing problem with research support services. Having all software run within one continuous framework — without requiring system-level access for supported users — makes it easier to give researchers the assurance required without frustrating them with the details.
The SIdora Software Environment
The software tools, standards, and practices resulting from digital repository management research and the web's continuing development provide a foundation on which to begin addressing this challenge. Although no standard exists for organizing and managing the components of this scholarly network, Fedora provides a conceptual framework that can address its basic needs.
The Fedora Commons implementation provides a repository management platform with the components necessary for information management. It stores digital content as a set of files (digital objects) that do not depend on the Fedora software to be understood. Also, the information needed to assure each object's durability is stored in files that are machine- and human-readable. These digital objects can be made available to software applications as flexible, policy-enforced, linked data.
Information Architecture
In SIdora, information is managed as "information objects," each of which represents one unit of content. The objects provide an identity for all of a unit's associated components (including content files, metadata files, policies, and audit trails). Each object can assert a formal relationship with any other repository object using a link defined with the Resource Description Framework (RDF). In theory, these relationships can also point to any compliant resource on any server in the world. This allows for aggregations of related information objects that can represent complex resources, such as research projects, and positions them to participate in the evolving global network of linked data.
The SIdora architecture has two primary types of information object:
- Concept objects are digital instantiations of ideas or concepts in a particular context or digital surrogates for physical objects, entities, or processes. They are essentially descriptive metadata that provides a formal node in the creation of a linked-data context.
- Resource objects organize all of a digital artifact's components, such as images, video clips, tabular data sets, or gene sequences.
As figure 1 shows, concept objects can have child concept objects, which are infinitely recursive and related to any number of parents, while resource objects are the immediate children of one or more concept objects.
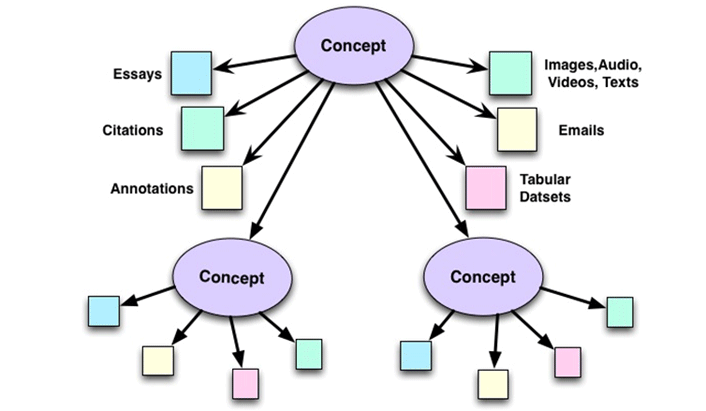
Figure 1. The SIdora object model
Given this, a SIdora user can construct a conceptual description graph as an intellectual model to organize digital resources in arbitrary ways. A concept object must have only a title in its metadata, which means that a user can initially sketch out the context — similar to a linked-data directory structure — and later add more metadata to each concept to enhance the graph and create a richer database. Thus, users can quickly establish an intellectual model outline and use it to organize resources as the resources are gathered; they can later build out this model as they analyze the resources.
A project always starts with a project concept object that establishes the root node of the project tree (similar to a website's home page). However, it can quickly grow into a graph. A concept can be the child of more than one concept, as can a resource. For example, in an archeology project, a pot can be represented in a conceptual tree that captures the semantics of excavation, showing where the pot was found in a tomb, as well as in a tree that represents the analysis of pottery found at one or more sites. This lets users establish multiple simultaneous contexts, each of which represents a different line of analysis for the same set of data.
Concept Objects
Concept objects are the basic information objects used in a digital artifact's context within the project. SIdora offers users a list of concepts [http://oris.si.edu/smithsonian-concept-ontology] as they build out their project. As I noted above, a concept can be represented with a title only, creating what is basically a linked-data directory structure. With more effort, the concept objects can hold rich data, enhancing the graph to become an elaborate database (For more information on this, see the Smithsonian's concept ontology [http://oris.si.edu/smithsonian-concept-ontology].)
A concept object's content is essentially a metadata record [http://oris.si.edu/sidoraconcept-descriptive-metadata]. SIdora matches the concept type with a specific XML data editing form designed to provide information relevant to the concept being described in the specific context.
Resource Objects
SIdora establishes a content model and workflow to support each data type added to the repository. Each resource type has a wizard that lets users upload one or more content files from a supported set of input types and enter metadata about it. For each uploaded content file, a Fedora object is created that holds the content file and user-provided metadata. When the user finishes uploading a set of files, SIdora initiates an asynchronous backend process that runs a set of services; these services create an archival version (if it was not submitted), add additional descriptive and technical metadata, and create content derivatives.
New resource types will be implemented as demand arises. Right now, SIdora accommodates basic bitmap images, PDF files, tabular data, and basic audio objects. The development team is currently working on new resource types to support basic video and assembled gene sequences, and we're planning for many more types, including 3D and vector images, GIS data sets, and software code objects.
SIdora Functionality
Clearly, SIdora's success will hinge on giving researchers immediate, highly useful results that outweigh any extra effort needed. It is also clear that supporting the complex array of research activities at the Smithsonian will be impossible unless we find a way to provide an integrated environment with standardized software tools that can work together to ensure the smooth movement of data among all necessary states.
Figure 2 shows a conceptual framework for how we're developing the SIdora environment to accomplish this. The basic assumption underlying this framework is that, over time, we can provide an environment of integrated software tools that meets all researcher needs. The key to ensuring information sustainability and reusability is to get it into a repository as early in the process as possible.
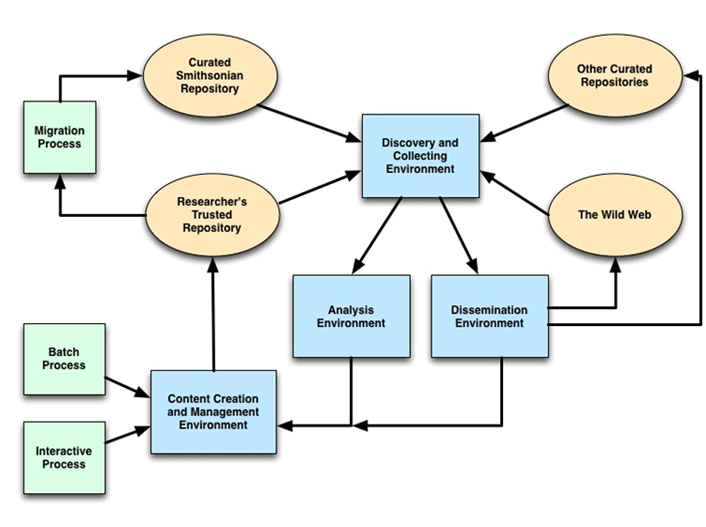
Figure 2. The SIdora conceptual framework
In figure 2, the Researcher's Trusted Repository represents the managed content's initial state: the researcher (content creator) retains complete control of the content and can set policies about how others can use it (or not). The Curated Smithsonian Repository represents the information passing from the original researcher's control to its long-term institutional home. This might be simply a logical separation, in which the data stays in the same repository and the ownership shifts to the institution, or the data itself might move from one repository instance to another (perhaps even one outside the original supporting institution's boundaries).
The four environments represent virtual spaces in which users can access software tools and services as sets of use-case-specific interfaces and workflows: Content Creation and Management creates new information objects in the Researchers Trusted Repository. Discovery and Gathering lets users search and gather data from their own collections and other repositories and process it using an integrated set of software tools in the Analysis and Dissemination environment. In both cases, any digital content created can smoothly flow back to the Researchers Trusted Repository to be added to their projects.
The SIdora project is developing a new software workbench that integrates these four functional areas. Although this effort involves the development of new software, much of the functionality — particularly in the Analysis and Dissemination environments — integrates existing software tools.
Content Creation and Management Environment
This environment, the workbench's foundation, gives users the ability to upload data to the repository, describe the data, create an intellectual model to organize it, control the data access policies, and manage and change the data over time.
To extend the graph of objects, users first select a concept to work on. Initially they see only the "researcher" object that came with the account. They build out that object by adding concepts recursively to expand the graph (much like they would a file system's directory structure). Users can also add resource objects as children to the selected concept.
Figure 3 shows the SIdora workbench interface. The concepts graph browser is on the left side of the pane. When users choose a concept, the concept metadata is formatted in the concept pane, which includes a menu of possible actions. In figure 3, for example, I chose the "add a concept" action, which opens the top-level list of concepts. I then selected the "place" concept, which has three specific types of place. Selecting one of these concept types kicks off the workflow to create a new concept object.
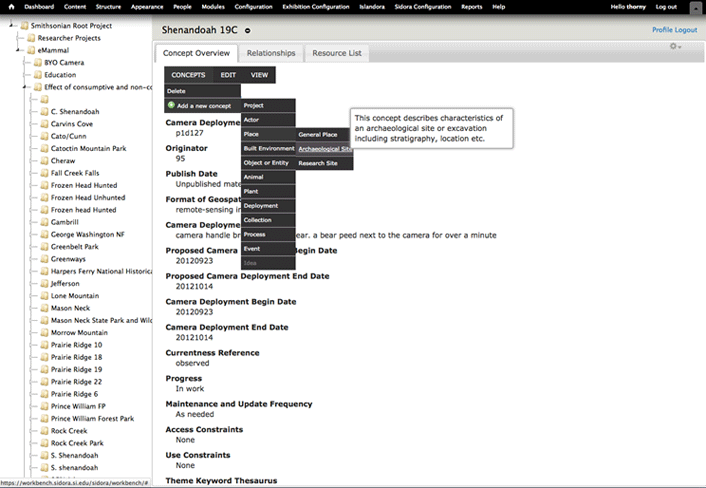
Figure 3. Adding a new concept object
Figure 4 shows a set of resource objects (here, a group of images) directly associated with a chosen concept. When the user selects a resource, the resource overview pane opens on the right. This offers access to the descriptive metadata for the selected object, while the relationships pane shows the resource's relationships to one or more concept objects, and the viewer pane shows a preview of its content. As the central pane's open menu shows, users can add resources by clicking on "add resource" in the menu; doing this displays a list of supported resource types.
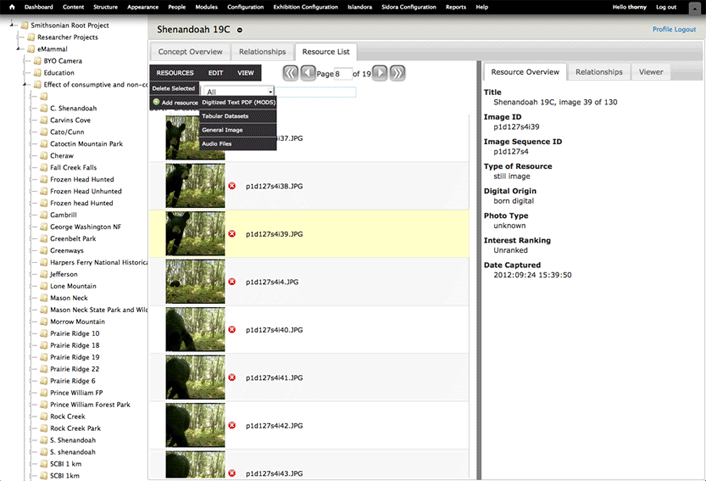
Figure 4. Adding a new resource to a concept object
When a user clicks on a resource type a software wizard initiates a set of interactive steps to upload one or more content files; to create (or use an existing) codebook, if applicable; and to enter descriptive metadata for each uploaded file. When the user has finished the upload, an asynchronous process launches to run an Apache Camel route, which finishes creating the appropriate set of objects, adding metadata, and creating derivative content as appropriate.
In all cases, each new child object is owned by the parent from which it was created. The relationships are written into the parent object's content as a "hasConcept" or "hasResource" relationship that ties them together. This ensures that users can assert a claim to objects to which they have access without writing to the content of another user's object.
Discovery and Collecting Environment
This is the workbench's search interface, which also lets users assemble temporary data "sets" from the repository to use in their analysis and dissemination activities. Initially, this gives users access to only two types of repository data: their own data and any data for which they have access permissions. In the longer run, however, this environment will become the attachment point that lets users collect data from interoperable repositories and the open web (as figure 2 shows).
Analysis Environment
In this environment, users can connect to well-behaved software tools to analyze the data sets they assembled in the Discovery Environment. One way we plan to build these connections is by using analysis execution frameworks, such as Galaxy and Taverna, that already integrate many generally useful tools.
We will also write connectors to convert SIdora sets to sets appropriate for existing frameworks. In addition, we plan to build a default connector that converts a SIdora set to a local file system on the user's desktop, much like DropBox. Finally, with management workflows users can easily add any new data created in their analysis activities to the repository.
Dissemination Environment
Similar to the analysis environment, this area will connect data from the repository to well-behaved software tools useful for publishing or sharing repository data. The same type of connectors developed for the analysis environment will be used to connect users to publishing tools.
Currently, SIdora provides an exhibition tool that lets users share project information with others through an automatically generated website. Users can expose any concept object as a web-based exhibition, which includes the object's content, a list of all immediate child resources, and navigation links to linked concepts and their resources. The resource content and metadata can be viewed and downloaded interactively. Users can choose from among a few simple exhibition layouts using SIdora's configuration tool.
Software Development
The current version of SIdora (version 0.4.1) is a complete rewrite of the initial 2012 prototype. The code base is written in Islandora 7, running on top of a Fedora 3.8 repository. We replaced Islandora's micro services engine with one we developed using Apache Camel.
SIdora is an open-source project, and the code is available in a GitHub repository. (The SIdora project page [https://oris.si.edu/sidora] has more information.) We are actively seeking to establish a collaborative community to continue developing the code base. SIdora's general development requires programmers well versed in RDF, Drupal, Java, and XML, with more specialized experienced in various digital media required for developing new types of resource objects.
As the code base evolves, we want to make SIdora more configurable. A great benefit of basing SIdora on the Fedora architecture is that its data objects contain much of the logic that other systems would have in their software. That fact, combined with SIdora's overall linked-data orientation, assures that the information network can grow organically over time, tolerating new data types, new relationship types, and other new architectural details with relative ease.
SIdora Pilot Projects
Although clearly ambitious in its long-term goals, we designed the SIdora project for initial development among a few researchers and later expansion. The current pilot version now provides enough of the described functionality to begin working with a larger group of researchers; these early adopters will work toward developing a level of functionality that should ensure wider adoption.
We launched two SIdora prototype projects, as follows, to begin validating the model.
Excavation Data Pilot
The goal of the first test project is to capture all of an archaeologist's excavation data from his many digs in Panama over a 40-year period. Archaeologist Richard Cooke is a senior staff scientist in archaeology at the Smithsonian Tropical Research Institute in Panama. A grant from the Andrew W. Mellon Foundation let us hire staff to digitize Cooke's data, both paper and photographic artifacts and data in spreadsheets. We are approaching a complete record of his excavations, which now consists of more than 4,000 concept and resource objects in the repository. Cooke has been entering metadata for two years, as has his project manager. As Cooke noted, the benefits of SIdora to his project and beyond are clear:
"SIdora has enabled me to convert 40 years' worth of images, spreadsheets, and archaeological data into a coherent integration of past research with novel approaches and methodologies, thereby improving our understanding of the social evolution and ecology of ancient Isthmian cultures, and their connections to surviving Native American peoples."
Now that Cooke can analyze the data, he's made connections across his sites, illuminating new research directions that he's now pursuing. As this project demonstrates, for some researchers, simply being able to manage all of their data in one place is enough benefit to make the system useful.
Camera Trapping Pilot
The second main pilot is an international camera trapping project that studies animal populations by gathering large collections of camera trap images and analyzing them to create files of animal observations at specific times and places.
We developed a prototype application programming interface (API) to query across the graph of concept object metadata that describes sites and camera deployments; this lets researchers gather and aggregate the observation files as tabular data, which is then run through R workflows to analyze it. We also built a first Apache Camel-based process for that project; the process retrieves data packages from the cloud and unpacks them to add concept and resource objects to the eMammal objects graph (see figure 4). The camera trapping project's repository now includes more than three million objects.
Planned Pilots
With the experience gained from these first projects folded into the new pilot version of SIdora, we are ready to take on more projects. The next round of pilot projects will involve the following researchers:
- an archaeological conservator, who studied gold objects excavated in Panama;
- two groups of biologists — one studying birds and the other studying coastal marine life and ecology;
- a group of anthropologists and archaeologists working in Mongolia;
- a curator at Smithsonian Gardens who creates an exhibition of orchids every year for the Natural History Museum; and
- a taxonomist studying insects.
Torsten Dikow, a research entomologist at the Smithsonian's National Museum of Natural History, will be participating in this round of pilots and looks forward to unifying — and making accessible — his many years of research.
"As a researcher interested in open access and sharing research data, the opportunity to capture in digital format an entire project, archive it, and make it accessible along with the scholarly publication is wonderful. The individual projects will add up so that by the time I am going to retire, a complete record of my research will be accessible to all."
Paula DePriest, the deputy director of the Smithsonian's Museum Conservation Institute, will be another pilot researcher in the next round using the information that she gathers in her yearly surveys of Mongolian sacred sites.
"If we can use SIdora to manage the digital output of all kinds of Smithsonian research projects in Mongolia, then it may offer a practical solution to Mongolia's larger data crisis. In addition to providing the Mongolian cultural heritage community with a single, secure, and researchable archaeological management system, establishment of a central repository would stimulate sharing of data among researchers and institutions, and the repatriation of data back to Mongolia."
Conclusions
At this point, I believe we have a good proof of concept for SIdora and have achieved initial success in its use on real projects. However, much work remains to make it more useful and intuitive for researchers to apply. SIdora's basic architecture provides a generally applicable way to organize digital resources and provide an intellectual context for them, usable by any kind of research project. I hope that others will find SIdora a good starting point for collaborating with a user community to develop a rich toolset on top of the basic SIdora platform to support specific disciplines at a much higher level. If this is possible, I believe that a truly interoperable research support environment may evolve.
Clearly, an approach based on a library metaphor — that is, a perfect collection with its perfect search interface — is inadequate for the task. But, simply slapping a layer of RDF-based linked data on top of the existing web is not the answer either. The SIdora project aims somewhere between: providing trusted, durable digital information in the initial stage of the research data lifecycle and growing it as part of a truly interoperable web-based scholarly and scientific record.
I believe researchers should become directly involved in describing and organizing the information that results from their activities. Getting them to do this, however, has often been compared to herding cats. It has also been said that the only way to herd cats is to tilt the floor. Funding agencies and government decrees around the world have begun doing this by requiring data management plans for research grants. It remains to be seen whether researchers can be enticed into creating their own metadata and organizing their own content. The early evidence at the Smithsonian suggests that they will.
Thornton Staples is director, Office of Research Information Services at the Smithsonian Institution. He co-directed the Fedora Project. At the University of Virginia he started an R&D department in the library and was the first project director at the Institute for Advanced Technology in the Humanities. He has consulted on information architecture and research support with the American School for Classical Studies at Athens, WGBH Broadcasting, The Interuniversity Consortium for Political and Social Research (ICPSR), University College Dublin, La Trobe University, the UK Arts and Humanities Data Service, and the Biblioteque Nationale de France.
© 2015 Thornton Staples. The text of this EDUCAUSE Review article is licensed under the Creative Commons BY 4.0 license.