
It is time to rethink the digital experience in higher education: we have a chance not only to reimagine our encounters with the large scale but also to embrace our opportunities at the other end of the scale.
William G. Thomas III is Chair of the Department of History at the University of Nebraska-Lincoln and is the John and Catherine Angle Professor in the Humanities and Professor of History. Elizabeth Lorang is Digital Humanities Projects Librarian for the Center for Digital Research in the Humanities at the University of Nebraska–Lincoln.
The landscape of teaching and research in higher education has changed dramatically in the last decade as we have moved more and more of our practices, materials, and communications online. Campus classrooms and public spaces have been wired for access, course materials digitized, and learning management systems installed. Many libraries have obtained a scale of electronic resources we could not have imagined for most print-based collections. Various entities, including governments and corporations, have combined massive digitization efforts, large-scale data repositories, and high-speed connectivity to constitute new forms and modes of knowledge representation, indexing vast collections and providing hierarchical levels of accessibility.
These hierarchies come in different forms and are deeply embedded, so they remain largely invisible even as students and faculty routinely navigate them. One set of hierarchies is imposed through structured data, since certain types of information are privileged over and against others in any given query or interface. Another set of hierarchies governs access, since certain classes of individuals obtain different kinds of data based on their status.
This new landscape means that faculty, students, and IT professionals in higher education are confronted with a series of almost daily instances in which choices about the design and outcome of their digital engagement tilt the scale toward either absence or presence, activity or passivity, the open web or system closure. Faculty members have rarely been asked to assess the pedagogical value, purpose, cost, and implications of these seismic shifts in tools and practices. Adaptation has often been administratively driven, characterized by the search for "system" solutions.
The move to the digital environment has been championed with rhetoric of openness, accessibility, and ubiquity even as colleges and universities paradoxically have arranged teaching and research environments that are increasingly closed, offline, uneven, and gated. All of us in higher education talk with lofty idealism about the necessity of digital engagement in our classrooms and research environments, but we rarely ask what kind of engagement we want and on what terms.
The ambitions at the heart of the early introduction of the Internet into higher education—including opening the university to the communities of knowledge, education, and local people who could participate more in its work—seem quaint or idiosyncratic in the present search for "enterprise" solutions, but it is precisely these early expectations that could and should be recovered and reinvested in now. The fundamental problems with the current terms of our digital engagement are that too much has been lost, unimagined, ceded, and assumed.
Much of the discussion about technology in higher education proceeds from interlocking sets of assumptions: that every student and community has access to the same level of technology; that we are breaking down walls in higher education; and that computationally enabled ways of knowing enhance every question. But there is a critical gap between the rhetoric and the reality of how higher education is engaging the digital: the reality is a relatively closed, incomplete, non-community-based, and highly privileged system.1 We need an alternative modality of engagement with the digital on our campuses—one built around reciprocity, openness, local community, and particularity. This model may be more sustainable, more productive, and more native to the medium.
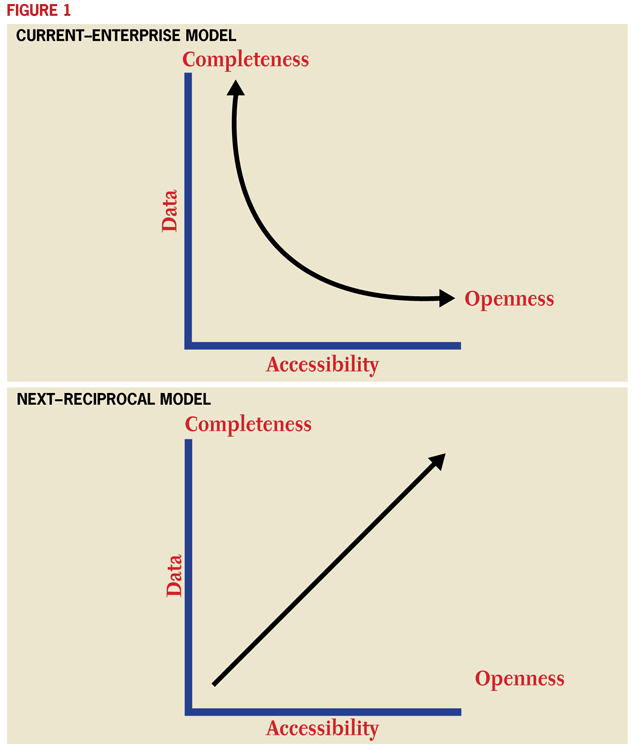
If we develop our research and teaching in the open web, build highly integrated and open networks of scholarship into our teaching and learning, and enlist local people to participate with us in these endeavors, we dramatically shift the terms of digital engagement. New techniques and forms of digital engagement will be required, and at the same time, older modes of disciplinary inquiry will be preserved, carried forward, and reconstituted. The current model of digital engagement can be characterized as "enterprise" in its approach: the larger the data volume, the less accessible and the more proprietary it is. A model characterized as "reciprocal" centers on a fundamental reorientation: each step of additional data corresponds with an equal step toward its open accessibility.
Rethinking Scale
First, we need to bracket the present enthusiasm for "big data" and the often blindly idealistic notions of what the large scale will do for us. The perceived paradigm-shifting potential of data mining and corpora analysis—of turning artifacts into data, aggregating them, and analyzing them computationally—has fueled a race for funding and legitimization. Understandably, digital scholars want to believe that enough computational power and enough data will help them produce greater knowledge, obtain deeper original insight, and achieve more authority. Indeed, such methods do afford opportunities: personally, we (the co-authors) have been or are involved with big data projects, and the two of us collaborate with scholars using computational and statistical methods to "read" millions of books and other textual materials, processing tens of millions of words and making new associations and connections.
Nevertheless, a broader epistemological concern is at stake with the move to large-scale computational analysis of "big data." Scholars enter or manipulate data that is bounded, is historically constructed by others (in many cases), and is therefore capable of rendering a predefined set of possible outcomes. In the humanities, the data, whether big or small, is constitutive of the mental categories and political strategies of its originators.2 Analyzing discourse, not crunching data, has allowed scholars to break down the symbolic culture of gender and race, of what made these categories and what held them together in society. As a result, in some scholarly quarters big data appears to be obscuring the very real gains made by humanists over the last twenty years, possibly threatening the political project they have undertaken as well. What we already know becomes, paradoxically, what is known and what is knowable or discoverable.
Advocates for big data assert that the computational search for patterns in the human experience will unlock or reveal self-evident meanings and lead to important new discoveries, yet they offer no particular model of human behavior or social or economic theory to test against the data. Instead, the data, if large enough, is treated as ipso facto representative of culture in its totality. Geographical, technological, and material determinism often characterizes the outcomes of these investigations, and all types of individual, cultural, and social actors and creations are elided. In many quarters of the humanities, the political and ideological consequences of this move appear reactionary, threatening to efface decades of scholarly work in order to incorporate marginal, noncanonical voices and to read into the records of the past the full spectrum of humanity.3
Although social science history has been explicitly empirical and material, even the historians most committed to the analysis of data have long conceded that the object of study is indeterminate and that the data objects offer a limited, if very powerful, means of knowing the past. Yet approaches in evolutionary biology and mathematics have influenced, even emboldened, historians and literary scholars alike, suggesting that the search for the hidden "code" of humanity and human society is a viable transdisciplinary project. The social science historian Tim Hitchcock, a close observer of these trends, has worried that in the rush to mine big data, humanists find themselves asking only the questions that computers can answer: "Our practise as humanists and historians is being driven by the technology, rather than being served by it. . . . Having built our theory on the sands of textuality, we need to re-invent it for the seas of data."4
Underlying the rhetoric and applications of big data are a number of assumptions about data completeness and integrity. Large corpora appear universal; major data sets suggest coherence. Yet the gaps in large corpora and the missing links in data sets, as well as the methods used to create them, deserve deeper scrutiny. The current model of digital engagement around big data anticipates continuity where there is often discontinuity, wholeness where there is often incompleteness, and uniformity where there is often selectivity.
The example of the Queering Slavery Working Group stands in contrast to the high-profile methods so dominant in higher education digital discourse as of late. At the April 2014 Nebraska Forum on Digital Humanities, Vanessa Holden, a Michigan State University history professor specializing in the history of American slavery, noted: "You cannot find in the archive what you cannot imagine."5 Her work suggests, quite literally, that we have not been able to imagine queerness in slavery and that doing so will require an intervention into historical imagination.
To make this intervention, Holden and her colleagues in the Queering Slavery Working Group (#qswg) use Tumblr to release images of 17th-, 18th-, and 19th-century slavery with superimposed hashtags drawn from the resistance and survival vocabularies common in the queer and drag communities of the 1980s and 1990s. They contend that knowing something about slavery requires provoking a culture that today is so similarly marginalized that "reading" and language are constantly deployed to walk a line between compliance with and resistance to social norms. For example, #thelibraryisopen is paired with the image of a doting white master and a young slave boy from the 18th century, and an image of a runaway slave notice from a 19th-century newspaper appears with the hashtag #out. Both posts include full provenance and citation information.6 The working group's use of these intentional anachronisms may seem decidedly ahistorical at first glance. But the intended cumulative effect of the group's use of the digital medium is to open a new way of knowing and of imagining slavery.7
Significantly, Holden and her colleagues are not using digital technologies or tools primarily to discover a "finding" or to algorithmically deduce patterns otherwise impossible to see. Instead, they are exploiting the digital medium to reconstitute how we can see the past through a more open, community-based, and reciprocal form of engagement.
Taking Advantage of the Open Web
All aspects of the digitization life cycle and the methods we bring to digital content for research and teaching allow us to know in certain ways and not others. Perhaps no quality of our digital engagement has been less discussed than how these affordances are configured and what they might mean for knowledge production in the future. Although mass digitization and the standardization of materials create large pools of resources ideally open to all, they also cause unique items to be discarded. The Google Books or HathiTrust copy(ies) might become what everyone consults, while the uniquely annotated or provenanced library editions might fade so far into the digital depths that no one will be able to discover them, much less study them. Although these digital projects allow us to address questions of genre, authorship, and literary form at an unprecedented scale using millions of texts, scholars risk losing other types of inquiry and ways of knowing. Even the largest of these digitization projects contain vast, often hidden, gaps in the accessible data, whether because the digitized collection was uneven in its scope or because the rights to include all of the texts could not be obtained.8
In library instruction and in classrooms across campus, moreover, present models of digital engagement obfuscate what access to digital information often means. In particular, students find sources, obtain information, and perform their academic work unaware that they do so only because someone has paid for it. In addition, by using subscription databases on campus, students agree to abide by terms of service they may never see, unless they seek out these terms. In short, colleges and universities accept and model for students the passive use of digital resources. There is widespread concern about how students skim the surface of the "deep web" and over-rely on Google for finding information, but those of us in higher education have done little to help our students understand what it means to have a deep web of information. We have not required most students to grapple with the fundamental issues related to information access and information ownership. We require them to use databases for research and demonstrate their ability to find articles, but we do not generally require that they understand, let alone question, the complex set of values and hierarchies in these collections.9
On the other hand, digital scholars across a number of disciplines are moving to outmaneuver these closed systems and proprietary applications by creating more suitable tools for teaching and learning. Researchers at the City University of New York and the Graduate Center, CUNY have developed Commons In A Box (CBOX), an open-source software kit for running a shared community space to exchange ideas, research, and data. The Public Library Of Science (PLOS) and ArXiv have become widely used and recognized nonproprietary models of scholarly communication in the sciences. Scholars at the University of Southern California and in the Alliance for Networking Visual Culture are building Scalar, a common platform for publishing interactive, rich-media scholarship in emerging genres on the open web.
Still, despite these innovative examples, higher education has yet to adjust many of its core practices to the affordances of the open web. With so much of the learning environment locked down in learning management systems, the opportunity of the open web remains largely untapped.10 Many instructors link out to the open web for a few readings or assignments, but in general they cordon off the classroom and other information environments. Such a barrier ostensibly serves to protect the identities and work of students, as well as to protect arrangements that institutions may have with content licensors and clearly identify "educational" use and access. Indeed, the intensity and scale of this mediation runs counter to one of the principal affordances of the network: openness— or what Yochai Benkler has called "commons-based strategies of information production."11
For those students who do participate in courses that present their work in the open web and that interrogate the terms of digitization, the experience catalyzes deeper learning.12 One way to proceed in this direction is to involve students as collaborators in ongoing research projects. Tufts University Professor Gregory Crane, Editor in Chief of the Perseus Project, has recently drawn attention to the need for "a new culture of learning" not only for the field of classics but also more broadly. According to Crane: "We need to engage our students and fellow citizens as collaborators. We need a laboratory culture where student researchers make tangible contributions and conduct significant research." Crane argues: "The crush of data challenges us to realize higher ideals and to create a global, decentralized intellectual community where experts serve the common understanding of humanity."13 University of Richmond President Edward Ayers also recently called for students to participate in a cycle of "generative scholarship." He suggested that students build their work alongside ongoing research projects so that their contributions can be assessed, validated, and preserved.14
Building Community-Based Pedagogy
Enlisting students in generative scholarship and research offers significant advantages, but these strategies on their own do not make students aware of the unevenness in the digital environment, nor do they necessarily expose students to their own assumptions about where knowledge resides. At the University of Nebraska, we are undertaking an effort—the History Harvest—to create a new model of undergraduate teaching and learning integrated through digital technologies, focused on digital ways of knowing, and based in communities of practice. We ask students to work in a self-reflective and active way to redress issues of loss, access, and absence through digital engagement.
The History Harvest courses engage undergraduate students in the development of an open, digital archive of historical artifacts that are gathered from communities across the United States and are then curated and prepared for interpretive scholarship. Each year, we partner with local institutions and members within a highlighted community to collect, preserve, and share their rich, but often hidden, family histories. Advanced undergraduates, working as a team and with the guidance of faculty members and graduate students, "harvest," digitize, and curate artifacts and stories. History Harvest is rooted in the belief that our collective history is more diverse and multifaceted than most people realize and that most of this history is found not in archives, historical societies, museums, or libraries but, rather, in the stories that ordinary people have to tell from their own experience and in the things—the objects and artifacts—that these people keep and collect to tell the story of their lives.15
From this vantage point, the present digital divide is less a function of access to the Internet and more a function of whose histories are accessible, which materials are privileged, and on what terms. The History Harvest thus affirms the importance of local people, local communities, and everyday experience in the broader narrative of U.S. history by providing an innovative opportunity for people to share their historical artifacts, and their stories, in a digital collection that forms the base for a more inclusive history of the community. The project brings into circulation artifacts and histories not usually represented in the current digital stream of data available to scholars and teachers. As these histories become digitally visible, the social and technical practices of openness and reciprocity gain new supporters in the community of scholars and with the public. After every harvest, the History Harvest's digital collection is available for educators, students and anyone else interested in engaging U.S. history from this more democratic, or grassroots, perspective. As a foundation for new scholarship, the History Harvest materials will be incorporated into the Digital Public Library of America and encoded in ways that support interpretive argument and new forms of scholarship.
The model for the History Harvest, moreover, is meant to be flexible and extensible—capable of being deployed in a wide range of settings and institutions. Teachers can build a mini-harvest into a much longer course or can devote an entire semester to a series of harvests and community engagement. The first edition of History Harvest courses focused on North Omaha, Nebraska: the birthplace of Malcolm X, a jazz mecca in the 1920s, and a predominantly African American community since the Great Migration. Other editions of the History Harvest will focus on South Omaha's Latino community and on other Nebraska neighborhoods and communities that are underrepresented in the digital space. We have also run an edition of the History Harvest course as a joint offering with the Computer Science and Engineering department, aimed at combining historical and computational methods and prompting cross-disciplinary training. In yet another context, we have organized the History Harvest in collaboration with local public schools and summer-enrichment programming, building stronger ties to the community. In addition, other colleges and universities have created their own History Harvest courses and archives, using our syllabi, resources, and tools.16
Through the open and public nature of the History Harvest, students experience a high level of accountability and community responsibility for the history they build. As History Harvest classes around the country work with and within communities and as students curate and interpret these materials for the open web, the possibilities for engagement multiply. It is precisely the hybrid formulation of this approach— blending elements of traditional classroom-based teaching with more recent calls for innovative, student-led and community-oriented approaches, along with digital and other technology-based methodologies— that has proven so powerfully transformative for teachers, students, and local communities.17
The History Harvest is a key part of a larger grassroots effort under way at the University of Nebraska to rethink the terms of digital engagement in higher education. Other examples include the undergraduate course "Being Human in the Digital Age," in which students examine salient issues surrounding how they create and use digital information and technology, and the Digital Humanities Practicum, where students work in teams to respond to digital challenges posed by faculty or outside organizations. For example, in the spring 2014 practicum, a team of undergraduate students worked with Humanities Nebraska, the local statewide humanities organization, to create a mobile application for the organization's Chautauqua program. The students channeled the populist spirit at the heart of Chautauqua and tapped into Nebraska's history of rural activism as they took up the challenge to communicate about Chautauqua to new audiences. The project required students to learn about Chautauqua and its history and to meld this older form of storytelling and interactivity with a new, digital way of conveying information. In particular, the students grappled with choosing one format over another to provide access and information, including the issue of who was likely to be excluded based on the decisions they made.
Toward Reciprocity
In other ways too, students and colleagues can learn to become active participants and leaders in the creation, dissemination, and reception of information and technical infrastructures. We need to look beyond established classroom environments and course structures. At colleges and universities across the world, for example, Wikipedia write-ins and edit-a-thons have introduced students and community members to the assumptions, biases, and absences of one of the most visited websites in existence.18 In a similar fashion, we might adopt strategies from the open-data and civic-hacking communities and have students evaluate institutional resources both for openness and for the variety of practical factors that can affect a user's access to information.19
Librarians and others are also developing innovative campus spaces, including incubators and maker spaces. Infused with the energy of the guild and with the ethos of the commons—in other words, with collaborative, self-reflective, critical, and active "making"—such places have the potential to make visible for many users what has been invisible, including political, social, and material hierarchies.
We must insist on and enact more reciprocal, open, and community-based terms of digital engagement in higher education. The present foregrounding of abundance and connectivity has emphasized volume and scale. The danger in this view of abundance, whether of rich data or of ubiquitous access, is a false sense of completeness and equality. To a surprising degree, we have ceded control and critical perspective in response to the promised potential of volume and the large scale. At the same time, we have accepted use models that exist in a highly commercialized and politicized environment.
It is time to rethink the digital experience in higher education: we have a chance not only to reimagine our encounters with the large scale but also to embrace our opportunities at the other end of the scale.
- On the problem of closure and the ecosystem of closed systems, see Jonathan Zittrain, The Future of the Internet and How to Stop It (New Haven: Yale University Press, 2008).
- Ever since the historian Joan Wallach Scott's devastating critique of positivistic research procedures in Gender and the Politics of History (New York: Columbia University Press, 1988), no historian can use data without questioning the categories the data established and reified.
- See Rens Bod, "Who's Afraid of Patterns? The Particular versus the Universal and the Meaning of Humanities 3.0," BMGN: Low Countries Historical Review 128, no. 4 (2013): 171–180, and Natalia Cecire, "When Digital Humanities Was in Vogue," Journal of Digital Humanities 1, no. 1 (Winter 2011). The #transformDH group has been an important voice in this debate: see Natalia Cecire, "In Defense of Transforming DH," Works Cited, January 8, 2012. See also Kenneth Pomerantz, "How Big Should Historians Think? A Review Essay on Why the West Rules—For Now by Ian Morris," Cliodynamics 2, no. 2 (2011).
- Tim Hitchcock, "Big Data for Dead People: Digital Readings and the Conundrums of Positivism," Historyonics, December 9, 2013. For an example of evolutionary biology and its influence on humanistic inquiry, see Alberto Piazza, "Evolution at Close Range," in Franco Moretti, Graphs Maps Trees: Abstract Models for a Literary History (London: Verso, 2005).
- Vanessa Holden, "Tumbling Towards Scholarly Community: A Report on the Queering Slavery Working Group," Nebraska Forum on Digital Humanities, conference presentation, April 11, 2014.
- The Queering Slavery Working Group: "#thelibraryisopen," QSWG Tumblr, December 5, 2013; "#out," QSWG Tumblr, December 7, 2013.
- See Omise'eke Natasha Tinsley, "Black Atlantic, Queer Atlantic: Queer Imaginings of the Middle Passage," GLQ: A Journal of Lesbian and Gay Studies 14, no. 2–3 (2008). See also http://qswg.tumblr.com/.
- On the complexities of mass digitization, see: Ben Schmidt, "Biblio Bizarre: Who Publishes in Google Books," Sapping Attention, April 3, 2014; Alexis C. Madrigal, "What Is a Book?" The Atlantic, May 17, 2014; and Charles Henry et al., The Idea of Order: Transforming Research Collections for 21st Century Scholarship (Washington, DC: Council on Library and Information Resources, June 2010). On the remediation and loss inherent in the transition to digital form, see Bethany Nowviskie, "Toward a New Deal," nowviskie.org, September 25, 2013. Calling for a new cohort of students and professionals engaged in digital work, Nowviskie has written: "Remediation, at its heart, is selective transformation—lossy and additive, a process of scholarly editing and interpretation—requiring the careful attention not only of content specialists, but of specialists in technologies of information, past and present, and in knowledge representation: people invested in the curation of things and the transmission of culture."
- See Barbara Fister, "Read/Write Culture: What Open Means for Learning, Research, and Creativity," presentation, ILA/ACRL Spring Conference, Kirkwood Community College, Cedar Rapids, Iowa, April 23, 2010.
- See Jim Groom and Brian Lamb, "Reclaiming Innovation," EDUCAUSE Review 49, no. 3 (May/June 2014).
- For an excellent summary table on the characteristics of enclosure and openness, see Yochai Benkler, The Wealth of Networks: How Social Production Transforms Markets and Freedom (New Haven: Yale University Press, 2006), "Overview of the Institutional Ecology," 395.
- See Marilyn M. Lombardi, Authentic Learning for the 21st Century: An Overview, EDUCAUSE Learning Initiative (ELI) Paper 1 (May 2007).
- Gregory Crane, "Greek, Latin and a Global Dialogue among Civilizations," October 26, 2012. See also Gregory Crane, "The Humanities in a Digital Age," presentation, Big Data & Uncertainty in the Humanities, University of Kansas, Lawrence, September 20, 2012.
- Edward L. Ayers, "A More-Radical Online Revolution," Chronicle of Higher Education, February 4, 2013.
- Patrick D. Jones and William G. Thomas co-direct The History Harvest digital project. For more on the project, see http://historyharvest.unl.edu/about.
- See, for example, Bill LeFurgy, "Engaging Communities to Preserve: The History Harvest as a Collaboration Model for Digital Preservation," The Signal: Digital Preservation (Library of Congress), September 4, 2013; William G. Thomas, Patrick D. Jones, and Andrew Witmer, "History Harvests: What Happens When Students Collect and Digitize the People's History," Perspectives on History 51, no. 1 (January 2013).
- William G. Thomas III and Patrick D. Jones, "The History Harvest: An Experiment in Democratizing the Past through Experiential Learning," presentation, IADIS e-Learning Conference, Prague, Czech Republic, July 23, 2013. Student privacy on graded assignments in the course remains intact. Not all student work is published on the History Harvest. The broader questions of student privacy and coursework are addressed throughout Brett D. Hirsch, ed., Digital Humanities Pedagogy: Practices, Principles, and Politics (Cambridge, England: Open Book Publishers, 2012), especially p. 295. In our courses, all work produced by students for final publication is edited by the project directors and published with agreement.
- For example, Brown University hosted an Ada Lovelace Day edit-a-thon in 2013, and in the spring of 2014, a series of edit-a-thons was held in memory of Wikipedia editor Adrianne Wadewitz. The Rewriting Wikipedia Project is part of a larger movement to affect who creates and is represented in entries.
- Two challenges posed as part of the 2014 National Day of Civic Hacking, for example, are relevant to thinking about the terms of digital engagement within institutions of higher education. One, the "Open Data Challenge," had participants create an open data report card for their city based on whether city data was publicly accessible and, if so, whether it could be accessed via an application programming interface (API). A second, "Digital Front Door/Digital Divide Challenge," had participants evaluate city and county websites for the "presence, findability, and mobile readiness" of key information.
© 2014 William G. Thomas III and Elizabeth Lorang. The text of this article is licensed under the Creative Commons Attribution 4.0 International License.
EDUCAUSE Review, vol. 49, no. 5 (September/October 2014)