
Key Takeaways
- Over the past six years, Purdue developed and continues to implement the Purdue Community Cluster Program, a collaborative model for high-performance computing that meets the needs of Purdue's research community.
- The PCCP leverages the benefits of both the central and local funding models to provide high-performance computing power to faculty, diminishing the need for faculty to operate their own system.
- A "coalition of the willing" is a successful model for collaboration that fits the research culture of the academy and can be adopted successfully by research-driven institutions everywhere.
At Purdue University, Thomas Hacker and Baijian Yang are associate professors of Computer & Information Technology, and Gerry McCartney is vice president for IT and CIO.
Rapid advances in computer technology have created new capabilities for discovery that are changing how scientists conduct research. Added to the traditional duo of theory and experiment at the core of the scientific process, the abilities to conduct detailed computational simulations and to perform analyses of increasingly large data sets are now indispensable tools needed by scholars to explore, understand, and decode complex systems. This emergence of the "third leg of science," well documented elsewhere,1 extends across all areas of human learning and research.
Thus, there is now an established and demonstrable need for accessible, reliable, and cost-effective high-performance computing (HPC) not only in the traditional computationally oriented fields of science, engineering, and technology but also in the humanities and social sciences. Research seeking to solve pressing problems affecting society, such as drug discovery and global warming, may even require the use of petascale computing capabilities. In the humanities and liberal arts, HPC is needed to digitize historical findings2 in fields such as archaeology. Indeed, HPC has already shifted research paradigms for scholars.3 The need for these faster computer systems with greater storage capacity has also spread to learning communities where, for example, some colleges are now allocating institutional computing resources to provide access to their learning resources for K–12 students.4 Figure 1 shows the growing importance of HPC-based research to the total research enterprise at Purdue University. Observe that while the total value of research awards has grown over the last 15 years, the percentage of that amount using HPC has increased tenfold, from 3 percent to more than 30 percent. This increase strongly suggests that institutions with significant research programs need to invest in their HPC in exactly the same way that they invest in laboratories and other specialized scientific equipment.
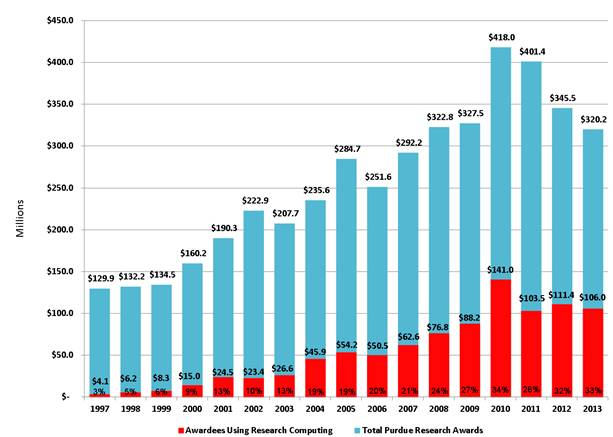
Figure 1. Percentage of awards to HPC users
The provisioning of this cyberinfrastructure service includes not only HPC but also data storage, visualization systems, advanced instrumentation, technical support, and research communities, all linked by a high-speed network across campus and to the outside world. What we now observe is that investment in campus-wide cyberinfrastructure has become a necessity whose quality is a key differentiation factor for research-intensive universities.
Key Marketplace Changes
In the past, access to high-performance computing was restricted by the expense of owning, operating, and providing support to technical researchers. But beginning in the mid-1990s, HPC architectures began to shift from custom-engineered and proprietary systems to a hybrid model that exploited the price-performance characteristics of commodity-computing technologies and open-source software. This trend toward commodity-based HPC systems can be observed in the historic architectural trends in the fastest Top 500 supercomputers list: in June 2000, only 11 supercomputers on this list were based on a cluster architecture; by June 2012, this number had increased to 407.5 The shift in supercomputer architecture and the fast growth in availability of powerful and affordable commodity hardware have enabled researchers around the world to build and own their own high-performance computers even with relatively modest budgets.
However, one of the key challenges facing a research institution seeking to support its research community is the need to accommodate ever-increasing computing demands in an era of flat or declining budgets. In this environment, it is essential to develop and explore new ways of optimizing the delivery of computing services within an institution. Beginning in 2008 and proceeding annually under the direction of co-author Gerry McCartney, Purdue University has developed and implemented a successful model for delivering HPC services to its research community with the intent of providing
- price leverage for the researchers for their research funds;
- access to resources in excess of their original acquisition; and
- a stable, managed, and secure HPC environment.
The evolving model we describe here is a synthesis of technical, economic, and sociological approaches that has allowed Purdue to develop a sustainable HPC infrastructure. In this article, we explore the economic and sociological factors affecting the research computing ecosystem that motivated the new model and describe in detail the model as well as its impacts and lessons learned over six years of implementation. It is our belief that the Purdue model represents a new and relevant collaborative approach that fits well with the research culture of the academy, one that can be adopted successfully by research-driven institutions everywhere.
Current Practices in Research Cyberinfrastructure
Hacker and Wheeler described the need to find a balance between centralizing IT operations and providing sufficient flexibility and freedom to allow researchers to innovate "at the edges" in individual departments and laboratories.6 It is clear that pursuing either 100 percent centralization (with institutional policies restricting activities at the edges) or 100 percent decentralization is undesirable from both effectiveness and efficiency perspectives. Pure centralization can stifle the innovation that primarily comes from the disciplinary edges and can impede researchers' progress. Complete decentralization can be tremendously inefficient, unnecessarily duplicating services and sapping the vitality of the laboratory research enterprise. The problem to solve at Purdue was to strike a balance between centralization and decentralization that would enable consolidation where it made sense to leverage professional staff expertise and economies of scale and to move control and choice to the center/department/laboratory level where innovations in the development, deployment, and use of cyberinfrastructure could be most quickly and efficiently implemented. It was also essential that the business model underlying any proposal be able to attract and retain the faculty researchers who were building and running their own clusters. We understood implicitly that wide adoption of any proposed model at Purdue would only be possible if there was extensive, positive word of mouth within the communities of researchers.
As noted above, an important transition had occurred at the turn of the millennium when the typical architecture of HPC began its transition from custom-engineered architecture to commodity-computing "pizza box" architecture, with much simpler node interconnects and a more freely and widely available operating system. This change enabled researchers who did not care for the service they received from their central IT organizations to build their own HPC clusters, which resulted in the proliferation of small "data centers" around campuses. (Here, we define a data center as an improved space having its own electric panel of more than 100 amps and an additional cooling capacity greater than 10 tons). In a 2007 inventory, Purdue identified more than 60 such data centers on the West Lafayette campus. Other research-oriented institutions report similar numbers depending on the relative size of their campuses.
Thus, the emergence of simulation and modeling as the "third leg of science," combined with the change in HPC architecture, enabled the proliferation of small data centers. The resulting proliferation of small data centers affected both power and cooling systems on campus and had unattractive outcomes for graduate students required to provide system administration services for their research teams. Simultaneously, there was skepticism, if not outright distrust, of any solutions offered by the central IT organizations, which labored to meet the growing demands of researchers, often by trying to apply standards and choices the research community did not embrace. As a result, there appeared to be only expensive and inefficient solutions. As Hacker and Wheeler noted: "Providing high-performance computing and networking resources as a part of research cyberinfrastructure is often the most costly and difficult information technology tasks facing an institution."7
A Continuum of Models for Funding Research Computing
We understand a central model to be an approach providing research-computing equipment, personnel, and operations funded from a large central organization (usually the computer center) that receives significant financial resources from the institution. The source of the funds may be general funds from the institution, or grant funds in which the central organization is the home unit of the principal investigator. In some cases the research computing group at a university reports to the institution's executive responsible for research (typically, the vice president for research or similar), in which case cyberinfrastructure is not seen as part of the IT portfolio but is considered a specialized piece of scientific equipment (like a radio telescope) requiring separate staff and a separate budget.
Likewise, a local model relies primarily on funds originating from the research group that is the major, and often exclusive, user of the cyberinfrastructure, which the group operates independently. The sources for these funds may be general funds, capital funds, or research grants. These funds may originate at the research laboratory, department, or college level, but do not typically come from the institutional level. Acquisition and management of these machines take place in a disparate and uncoordinated manner, often using standard university discounts for pricing with very little coordination of support for whatever hardware and software are acquired.
In contrast to these two approaches, Purdue sought a collaborative model to capture the benefits of the central and local models while removing their inherent weaknesses (see table 1). This joint investment/joint ownership approach self-consciously engages the central computer group with individual research groups whose work requires cyberinfrastructure. The essential characteristic of this approach is that it is a "coalition of the willing." By design, there is no institutional coercion — the arrangement is so attractive that it would be unwise for researchers not to participate. To be sure, nationally there are many worthy examples of groups of faculty coming together voluntarily to purchase jointly owned clusters, sometimes with central support. But what is different in the Purdue model is the simultaneous inclusiveness and extensibility of the business model, which was designed to encompass, at the outset, all the researchers on the West Lafayette campus.
Table 1. Comparisons of Three Different Funding Models
|
Local Funding |
Central Funding |
Collaborative Funding |
|
|---|---|---|---|
|
Sources of Funding |
Research groups, department, or college |
Institution |
Institution and faculty research grants |
|
Shared Cost |
No |
Partial |
Yes |
|
Shared Use |
No |
Yes |
Yes |
|
Service Quality |
Not guaranteed |
Professional quality, but users have no real control |
Professional quality and users' input matters |
|
Staffing |
May not have dedicated personnel |
Dedicated personnel |
Dedicated personnel |
|
Security |
Not guaranteed |
Professional quality |
Professional quality |
|
Sustainability |
Not sustainable |
Not sustainable |
Sustainable |
|
System Utilization |
Varies; likely to be lowest |
Varies; likely to be low |
Likely to be high |
Local Funding Model
Research sponsors usually fund the activities of individual researchers focused on achieving specific objectives; less frequently they fund large-scale integrated and comprehensive institutional activities. Research teams need access to capital equipment and cyberinfrastructure to successfully fulfill contractual obligations to the funding agencies. If the centrally funded cyberinfrastructure is inaccessible or unattractive to researchers, they are motivated to develop their own local cyberinfrastructure using funds under their control that come from grants and departmental and college-level funds.
Proponents of the local funding model claim the computing environment is built to precisely fit the researchers' needs. In practice, this is rarely the case; researchers usually buy the computing equipment with which they or the most IT-savvy graduate students are most familiar. The research team does, however, exert full control over its own cyberinfrastructure and should (in theory) have unlimited access to the computing environment they build.
There are obvious intrinsic limitations of the local model. First, the customized computing environment researchers build may not be sufficiently powerful to fully support their work, as their funding has to buy not only computing capability but also storage, interconnections, racks, cabling, and networking equipment, which all serve to dilute their purchases of computational power. Moreover, at an institutional level, the random sequence of small-scale purchases made over time through this funding model makes it impossible to exploit any negotiating power that would otherwise have been possible through a larger (> $1 million) acquisition program, even spending exactly the same amount of money when aggregated at an institutional level. This poor coordination leads inevitably to higher-than-necessary expenditures. Another limitation of the local model is the inefficient use of campus office or laboratory space, which is always scarce and costly. High-performance computing systems are literally hot and need specialized spaces that can provide adequate power and cooling to function reliably. In the local model, small-scale high-performance computers are often crammed into inappropriate spaces that rely on inefficient and unreliable small-scale cooling units. Another limitation is the illusion of "free" labor provided by students and faculty. The management and operation of the local model facility typically fall on the shoulders of researchers. Rather than focusing their time and energy in their area of research expertise, faculty and their graduate students often spend valuable effort to install, manage, and troubleshoot their own cyberinfrastructure. Because they usually lack specialized systems administration skills, the resulting product is frequently unreliable and insecure and may be more of a liability than an asset to the institution. This is especially true for aging systems that researchers are reluctant to retire. To compound the problem, the average utilization of computing resources across all of these environments is often very low, and because of the variety of vendors and products chosen by the researchers, there is reduced possibility of sharing resources, which also impedes interdisciplinary and collaborative research.
All of these limitations conspire to levy a hidden "tax" on the research laboratory and the overall vitality of the university research enterprise. The only benefit provided for this "tax" is apparent faculty owner rights in the development and use of research cyberinfrastructure. While at first this may seem attractive, at least to research groups, over the long run most groups realize that the attendant owner-rights responsibilities do not contribute to their research output. Bichsel reported findings that "The strongest predictor [of research computing effectiveness] was the provision of an integrated set of services by [central] IT."8 Thus, we conclude that, for the research community, the local funding model creates too much fragmentation and distraction, dissipation of effort, and ineffective utilization of both institutional and faculty research funds, and as such is not a useful model to promote either scholarship or stewardship of resources.
Central Funding Model
To avoid the fragmentation of the local model, many institutions have adopted a model in which cyberinfrastructure is centrally funded and operated. This approach has immediate and obvious advantages over the local model. First and foremost, in the central model, researchers can use the cyberinfrastructure without the burden of building and maintaining computing facilities. Additionally, technology acquisition at an institutional level can be made on a much larger financial scale, which provides better pricing, more powerful systems, attractive deals for vendors, and more efficient use of financial resources for institutions and research sponsors. As an added benefit, a campus-wide cyberinfrastructure can reduce space and decrease energy consumption and can be much more secure and dependable when managed by professional IT staff.
A large institutional investment requires executive support (an investment of $5 million is typical), which is not always forthcoming. One approach to addressing the huge cost barrier of the central funding model is to first invest in and build the system, and then recover the cost by charging utilization and access fees. While this approach could achieve complete cost recovery, in practice this is often unrealistic. For instance, a 2013 report from the University of Michigan Advanced Research Computing Advisory Team (ARCAT) found that a campus-wide computing cluster initiative built on a full cost recovery budgetary model in practice is essentially 70–80 percent subsidized through research incentive funds, departmental funds, start-up accounts, and teaching accounts.9
The central funding model approach also requires thorough and inclusive planning to support faculty research across many disciplines. A major challenge of the central model is the need for open communication between IT administrators and faculty, along with an effective process for collecting user requirements and a process for analyzing and synthesizing these requirements into specific solution sets. Concomitantly, excellent project management and expectation management are necessary along with clear communication channels between the computer services staff and the faculty, laying out clearly when and how services will be made available as well as clearly defining how operational priorities for the HPC resource will be determined. When any of these elements do not function reliably, the resulting cyberinfrastructure may not effectively meet the needs of all, or even most, of the faculty. Consequently, faculty may perceive the campus-wide cyberinfrastructure as a resource that they have no control over or involvement in, one that's irrelevant to their work and costly to the institution. When researchers are unable or unwilling to use a campus-wide cyberinfrastructure, by necessity they will use their own funds to build their own small-scale cyberinfrastructure. If many researchers make this choice — and large R1 universities may well have several hundred researchers funded for HPC — this can result in an underused central system and a collection of local, inadequately used, and poorly managed systems.
A New Alternative: A Collaborative Model
We assert that a large-scale centralized and common cyberinfrastructure is vital to the success of the institutional research enterprise. To be relevant, the development of this cyberinfrastructure must be carefully planned and executed, and based on meaningful and frequent communication with faculty. It requires the support of upper administration and faculty; it must help promote the institution as well as the individual scholar's research; and it must be technologically cutting edge while remaining cost-efficient.
The driving philosophy behind the collaborative model is that research faculty are not merely the customers of campus cyberinfrastructure; rather, they are active co-investors in the campus cyberinfrastructure. The collaborative approach tries to find a path between a totally anarchic model (which we hope we have shown to be ineffective for all parties involved) and the autocratic "one size fits all" approach of the central solution. Put another way, it behooves research universities to develop a business model to support collaborative funding that empowers faculty and promotes their research while fully leveraging the institution's investment in facilities and IT staffing.
The collaborative model has several characteristics that distinguish it from the local or central models:
- Shared cost. It is based on distributed and cooperative funding from both local and central institutional sources. We should note that this concept of a shared cost philosophy is different from, and in contrast to, the more usual cost recovery approach. The shared cost model encourages faculty to be actively involved in the design/bid process, as opposed to waiting until the machine is built and then deciding if they want to participate (cost recovery). By following the shared cost principle, the central IT provider can offer competitively priced resources to compete with the commodity cost of resources that drive faculty to develop their own cyberinfrastructure as a substitute for central cyberinfrastructure while giving these same researchers a very active voice in the design of the resources.
- Key tenant group. Institutions employing the collaborative model will benefit from the early identification of a key tenant group, especially if they've not employed this model before. The participation of faculty who can make large investments (usually greater than $50,000 each) quickly creates a significant pool of capital that provides financial stability (and sparks the interest of potential vendors) along with a sufficient economy of scale to attract and sustain a large cohort of faculty who make only limited investments. The combination of a key tenant group with a large number of smaller/later purchasers creates a large overall package that focuses vendor attention and can easily accommodate many ongoing small investments from faculty after the initial acquisition.
- Long-term planning and professional project management. The collaborative model requires disciplined, long-term planning and professional project execution. Many major research grants support multiyear activities, so it is important to carefully plan and execute the development of cyberinfrastructure over a window of three to five years, with equipment retirement as a deliberate part of the planning process. To avoid operating hardware beyond its useful lifetime, a clear retirement date must be established at the time of purchase for the hardware. If the organization follows at least a biannual acquisition schedule, there will be little loss in functionality from retiring the oldest equipment.
- Frequent and predictable acquisition. In an era where higher education institutions must constrain expenditures, a large, one-time expenditure from central funds for cyberinfrastructure may not be the first, or even the tenth, choice of the executive leadership of the university. By committing to acquisitions on a frequent and predictable basis to match demand, it is possible to avoid the boom-and-bust cycles of overprovisioned and underutilized resources at the beginning of the cycle, and the expensive and wasteful use of equipment beyond the end of its useful lifetime. A more institutionally sustainable approach, and one more reflective of the annual recruiting of faculty and awarding of research grants, is to reliably and predictably spread out purchases over time in annual or biannual acquisitions.
- Timing for acquisition. Managing the timing of an acquisition and defining a process for resource acquisition is critical. Many vendors seek to meet sales goals on a quarterly or biannual basis, and sales forces are frequently provided with mechanisms to increase sales near the end of these periods. To best leverage these opportunities, early, clear, and consistent communication with vendors is essential. The definition of open and measurable metrics, such as price/performance ratio or energy in watts used for each floating point operation, can help the vendors meet a perceived price point and provide maximum value for the institution. Further, the provisioning of "loaner" equipment as part of a vendor's bid allows researchers to try out their code, measure its performance on various hardware, and ultimately make a more informed decision. Additionally, an open and well-defined acquisition process helps vendors work with their organizations to seek the best value for the institution. Similarly, from the perspective of the researchers (and prospective investors in an annual build) a well-defined, well-publicized, and predictable annual purchase cycle enables them to plan the most effective use of their research awards.
- Shared use. Finally, in terms of systems operations, the collaborative model can significantly increase efficiencies through shared use. Each academic discipline has inherently busy and slack periods based on, for example, conference deadlines and academic calendars, that shape the type of faculty research activity. In aggregate, when these busy periods do not overlap, faculty in the midst of a computationally busier period can expand their use of the cyberinfrastructure beyond what they have purchased using idle resources that are underutilized by other research groups in a computationally quieter period. This access to resources beyond what was originally bought by the individual researcher provides significant, zero-cost, additional value to researchers.
"In a time when you really need it, you can get what you paid for and possibly more, when available. And when you don't need it, you share with others so they can benefit from the community investment."
—Gerhard Klilmeck, professor of Electrical and Computer Engineering and Reilly Director of the Center for Predictive Materials and Devices (c-PRIMED) and the Network for Computational Nanotechnology (NCN)
Collaborative Model Case Study: The Purdue Community Cluster Program
The Purdue Community Cluster Program (PCCP) is the foundation of Purdue's research cyberinfrastructure. Over the past six years, Purdue has developed a successful collaborative model that meets the needs of Purdue's faculty research community by leveraging the benefits of both the central and local models.
The PCCP maintains and enhances the campus-wide cyberinfrastructure through aggregated acquisitions from institutional funds, research grants, and faculty start-up packages. By collecting voluntary investments from different sources, the PCCP has created a sustainable annual flow of funds for maintaining and updating research cyberinfrastructure. This process has the additional virtue of sustaining itself only when it meets the needs of the researchers. Because the amount of funds available through the collaborative model are greater than would be possible by relying only on institutional funds, it becomes possible to procure faster and more powerful supercomputers at a lower cost on an annual basis.
"I wouldn't have been elected to the National Academy of Sciences without these clusters. Having the clusters, we were able to set a very high standard that led a lot of people around the world to use our work as a benchmark, which is the kind of thing that gets the attention of the national academy."
—Joseph Francisco, William E. Moore Professor of Physical Chemistry, member of the National Academy of Sciences, and past president of the American Chemical Society
When the Purdue collaborative model was first implemented in 2008, the central computing organization was able to raise $750,000 from faculty, on a voluntary basis, to purchase the Steele supercomputer at a total cost of approximately $2 million. Purdue created a procurement schedule that allowed faculty to buy in to the system at attractive pricing for up to six months after the initial purchase. Because the per-unit pricing for Steele was better than individual pricing, several waves of faculty purchases occurred over a six-month interval after the initial purchase. Following this success, in 2009 Purdue raised $2.4 million to build the Coates system, the fastest campus supercomputer at the time at a Big Ten university.
Table 2 shows that the PCCP has deployed one sizable cluster each year for the past six years. Five clusters were ranked in the Top 500 list when they first appeared (the installation schedule did not allow for the Hansen machine to be benchmarked). The success of this collaborative model was quickly understood by researchers, and each new build attracted new faculty participation. The cumulative number of unique participating faculty has grown from 36 in 2008 to 143 in 2012. In June 2013, Conte was built at a total cost of $4.6 million, $2 million of which was contributed by faculty members from their research grants. In the June 2013 Top 500 list, Conte was ranked first globally among campus-based HPC machines.
Table 2. Details of Purdue Community Cluster Program (2008–13)
|
|
2008 Steele |
2009 Coates |
2010 Rossmann |
2011 Hansen |
2012 Carter |
2013 Conte |
|---|---|---|---|---|---|---|
|
Number of participating faculty (departments) |
36 (18) |
61 (25) |
36 (16) |
22 (11) |
36 (21) |
23 (15) |
|
Number of computational cores purchased through the program |
7,216 |
8,032 |
11,088 |
9,120 |
10,368 |
9,280 (78,880 Xeon Phi) |
|
Approximate system acquisition cost per core hour |
$0.028 |
$0.031 |
$0.027 |
$0.031 |
$0.037 |
$0.036 |
|
First appearance on Top 500 ranking |
104 |
102 |
126 |
— |
54 |
28 |
|
System TeraFLOPS |
26.8 |
52.2 |
75.4 |
89.9 |
186.9 |
976.8 |
|
Dollars per GigaFLOP |
27.02 |
21.84 |
16.58 |
13.28 |
10.52 |
2.86 |
It's no surprise that the cost per GigaFLOP (one GigaFLOP is one billion floating-point operations per second) dropped each year from $27.02 in 2008 to $2.86 in 2013, and that in each case these prices were significantly better than would have been available to faculty buying independently at that time. But with the rise of cloud services, Purdue also tracked the cost for a faculty member to buy similar services from an available external provider. To do this, Purdue tracked the normalized per core-hour costs of Purdue's supercomputers and compared them to other available external resources either commercially provided or for other institutions. Those external costs ranged from 4.5 cents/core hour to 13.9 cents/core hour. Over the same period, Purdue's fully loaded cost has varied between 3.1 and 3.7 cents/core hour. We wanted to be able to demonstrate that, based on the data available to us, faculty would get the best value for their investment by choosing to buy in to Purdue's annual cluster purchase, but we always left the final choice with the individual faculty member.
As the clusters were built, it became clear that there was a very significant unmet need for HPC resources at Purdue. And it also became clear from the rapid uptake of the faculty (see figure 2) that the collaborative model was attractive. Figure 2 also shows that the first two clusters (Steele and Coates) ran at unusually high utilization rates, often exceeding 90 percent over extended periods. It was only with the building of the third machine (which added to the overall capacity available) that loads began to fall to a more reasonable and typical number. As additional machines have been added to the clusters, the load numbers have typically hovered around 65 percent.
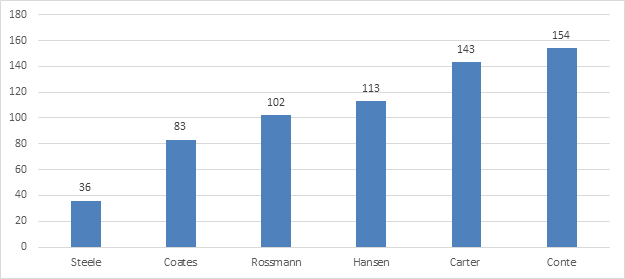
Figure 2. Cumulative number of unique faculty investors by cluster purchase
"For some of the tasks that we're looking at, just running on single cores we estimated that my students would need a decade to graduate to run all their simulations. That's why we're very eager and dedicated users of high-performance computing clusters like Conte."
—Peter Bermel, Assistant Professor of Electrical and Computer Engineering
One early casualty of the very high load numbers of the early machines (shown in figure 3) was the amount of time jobs had to wait in queues before they could begin work. Owners already had almost immediate access to the nodes that they owned, but an important part of the cluster proposition is access to nodes in addition to those that the individual researcher owns. While the machines were very busy, there were essentially no free nodes that weren't being used by their owners. The lengthy queue time for unused nodes is shown in figure 4.
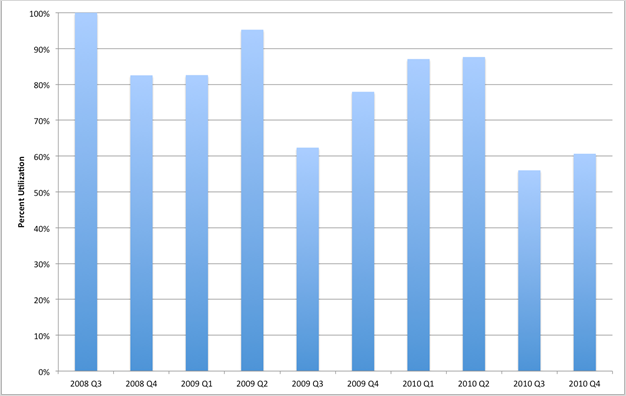
Figure 3. Overall utilization of the Purdue community clusters, 2008–10
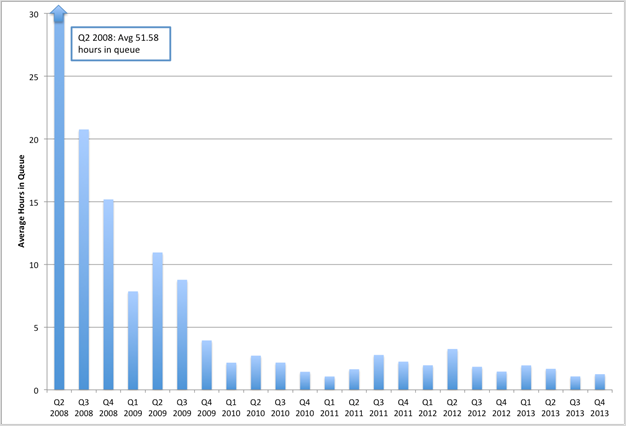
Figure 4. Average wait time, all Purdue community clusters, 2008–13
The early machines showed queue times often of more than 10 hours. As the second and third machines became available, owners were finding sufficient HPC resources to meet their research needs, and idle nodes became available to other cluster participants. This availability of nodes dramatically reduced the wait time for additional nodes, and the clusters were thus able to improve not only sharing of resources but also researchers' "speed to science" in a fairly dramatic way. Speed to science — the time researchers have to wait to get their results (waiting for the job to begin processing plus the processing time) — is an important indicator of performance for the Purdue's IT research support staff.
Typical Acquisition Workflow
One important key to the success of the PCCP implementation is a transparent, predictable, and reliable process surrounding the purchase of each cluster machine. The Purdue program consists of four sequential stages during an annual acquisition period that stretches over six to seven months, plus a fifth stage to retire old systems five years after implementation.
"ITaP completely took care of the purchasing, the negotiation with vendors, and the installation. They completely maintain the cluster so my graduate students can be doing what they, and I, want them to be doing, which is research."
—Ashlie Martini, Associate Professor of Mechanical Engineering, University of California Merced
- Planning Stage (December–January)
During the planning stage, researchers are surveyed to determine who might be planning to invest in this cycle, what their needs are, and how much they are planning to invest. Initial and exploratory meetings are held with possible vendors to understand their current offerings. Architectural options to meet needs and resource constraints are then explored and discussed with the researchers planning to purchase. Where possible, small versions of the proposed architecture are installed in the research data center, and faculty are solicited for typical codes to benchmark on the proposed machines. The final architectural choices are determined and passed to the business office to generate a request for proposals (RFP). - Bidding Stage (February–March)
The university purchasing group and the IT Business Office jointly develop and issue an RFP. The vendor responses are reviewed and clarified, and a summary document of the bids is prepared. The summary document (including where possible the performance numbers from step 1) is shared with the investing researchers and a winner is selected. - Deployment Stage (April–May)
Immediately after the winning bid is selected, the winning vendor is encouraged to either install a small unit or leave the unit that they provided in step 1. Site preparation is then carried out, including the provisioning of whatever power and cooling is required for the new machine. - Implementation/Production (June)
Following best practices, "friendly" users begin using the system as soon as practical. An important part of the "speed to science" narrative is to have machines in use as quickly as possible. In the case of the first machine (Steele, which was built in one morning), faculty were submitting and completing jobs by 1:00 p.m. on the first day of deployment. - Old Resource Retirement Stage (5 years after implementation)
Define decommissioning and user-migration plan for resources to be retired with each investing researcher. Individual equipment retirement agreements evolve into a policy over time.
Over time we have learned that the PCCP activities typically require about two additional staff FTEs; however, this is offset by the fewer technical staff needed to support the machinery. One staff member, dedicated to benchmarking and performance assessment, provides quantitative data for planning and acceptance testing. The other additional staff member coordinates the PCCP process, provides project management, and manages the PCCP project web pages to provide timely information to faculty.
Purdue Practices and Results
The best indicator of success of the Purdue program isn't purchasing, installing, and running the top-ranked computing clusters among academic institutions or the significant reduction in the cost to the researchers of compute power. The Purdue clusters are entirely a coalition of the willing; there is no compulsion on the part of the researcher from either the university or their departments. Indeed, there is also a standing offer that if ever a researcher is unhappy with their experience they may either take the hardware away that they own or get a prorated cash refund of their financial commitment (calculated on a five-year life span). Since 2008, cumulatively there have been 154 unique principal investigators from a pool of 160 to 200 compute-intensive PIs at Purdue who have become the shareholders of the CCP clusters. What is extraordinary is that as of this date none of them have left the CCP program since its inception six years ago; we consider this active and continuing faculty support the best indicator of the program's success.
"High-performance computing is critical for the modeling that we do as part of the National Nanotechnology Initiative. Without Purdue's community clusters we would be severely handicapped. They provide ready, ample, and cost-effective computing power without the burdens that come with operating a high-performance computing system yourself. All we have to think about is our research."
—Mark Lundstrom, Don and Carol Scifres Distinguished Professor of Electrical and Computer Engineering and member of the National Academy of Engineering
The success of Purdue CCP is also a selling point in recruiting new faculty. Having easy, voluntary access — with owner's rights — to one of the nation's fastest academic computing clusters without the overhead of constructing their own infrastructure certainly registers with faculty candidates. It also helps that colleagues in their home departments are using the same service. Acclimation to the CCP is thus quick and efficient for new faculty.
Additionally, the success of the PCCP helps retain technical staff in the computing organization and makes us a potential employer for graduating students. Given the size of the Purdue Clusters, the continuous flow of cutting-edge hardware and software, and the HPC staff's active participation in the PCCP, we can provide a credible and attractive professional environment for new graduates.
From our experience over the six years of the PCCP, we have discovered several principles of practice, which we summarize:
- Develop relationships with vendors. The ability to obtain good pricing is essential at the beginning of the service. Faculty may well stay because of superior service from a central IT group, but they will come initially because of attractive pricing.
- Cultivate the early adopters. The researchers who join the program at the beginning are taking a risk in doing so. At many universities, the central computing organization is not always held in the highest regard. Therefore, a service as core as research being offered by the central computing group requires something of a leap of faith from a participating faculty member. This "key tenant group" should be particularly nurtured for their leap of faith.
- Respect your project managers. The success of the program depends on being able to meet commitments. The building of our first computer, Steele, was completed in half a day. This wouldn't have been possible without a very effective project manager who marshaled the necessary resources to make it happen. This very public success provided a key message to Purdue's research community that we could make ambitious commitments and meet them.
- Build and capitalize on grassroots support. We noticed in the first several years that the program mainly propagates by department and research group. That is, once a respected researcher in a department or group bought into the PCCP, her colleagues would likely join shortly after. The inspiration of a respected colleague entering the program was very impactful in terms of encouraging other faculty in that department to join.
- Work closely with the institutional business offices. The business model of the PCCP has evolved since the beginning of the program and continues to evolve. This evolution demands a level of flexibility from the business services areas that can only be built on trust. It's important therefore to develop a good relationship with both the business office and particularly with the sponsored programs office (or whoever handles the administration of research contracts).
- Find seed funds locally to start. Particularly until the program has developed some credibility, it is generally advisable not to ask the central administration of the university for money. Certainly in these constrained times, it seems unlikely that a locally untested program will generate the needed level of support; therefore, it will be the responsibility of the CIO to find the funds for the initial project.
Conclusions
As research universities embrace computational simulation and analysis as the "third leg of science," the necessity of a cost-effective and relevant cyberinfrastructure for research and learning communities should be clear. We have argued that, due to its lack of scaling, high management costs, and institutional overhead, the local model cannot produce the optimal HPC resources for researchers. The central model is certainly more effective at providing integrated, campus-wide HPC resources, but the faculty surrender "owner privileges" and the attendant responsiveness and flexibility. The collaborative model described in this article highlights the successes of the Purdue Community Cluster Program. We believe that this is a success-oriented strategy for research universities in that it combines the most beneficial pricing model for faculty while still enabling them to retain their "owner privileges." The model is attractive to the host institution in that it enables it to meet a core faculty need in a cost-effective, reliable, and manageable way.
Resources
- Almes, Guy T., et al. "What's Next for Campus Cyberinfrastructure? ACTI Responds to the NSF ACCI Reports." EDUCAUSE Advanced Core Technologies Initiative report. July 2012.
- Almond, James S. "Condor Computing" [http://www.nacubo.org/Business_Officer_Magazine/Magazine_Archives/June-July_2009/Condo_Computing.html], Business Officer Magazine. June–July 2009.
- Hayes, Frank. "Frankly Speaking: Learning from IT Stunts." Computerworld. May 12, 2008.
- Jackson, Sally, et al. "A Research Cyberinfrastructure Strategy for the CIC: Advice to the Provosts from the Chief Information Officers." Committee on Institutional Cooperation Technical Report. May 2010.
- Jelinkova, Klara, et al., "Creating a Five-Minute Conversation about Cyberinfrastructure." EDUCAUSE Quarterly 31, no. 2 (2008): 78–82.
- McCartney, Gerry. "Better Than Removing Your Appendix with a Spork: Developing Faculty Research Partnerships at Purdue University." Presentation at the 2014 ECAR Annual Meeting, January 28–30, 2014.
- ________. "Information Technology: Purdue's Moneyball." PowerPoint presentation. February 2012.
- NSF Advisory Committee for Cyberinfrastructure Task Force on Campus Bridging. Final Report. March 2011.
- President's Information Technology Advisory Committee, Computational Science: Ensuring America's Competitiveness," National Coordination Office for Information Technology Research & Development, Arlington, VA (June 2005).
- Alison Babeu, Rome Wasn't Digitized in a Day: Building a Cyberinfrastructure for Digital Classicists, Council on Library and Information Resources publication no. 150 (2011).
- David Green and Michael D. Roy, "Things to Do While Waiting for the Future to Happen: Building Cyberinfrastructure for the Liberal Arts," EDUCAUSE Review, vol. 43, no. 4 (July/August 2008).
- Arden L. Bement, "Cyberinfrastructure: The Second Revolution," Chronicle of Higher Education 53, no. 18 , January 5, 2007; available to subscribers online.
- TOP500 List (as of June 2012).
- Thomas J. Hacker and Bradley C. Wheeler, "Making Research Cyberinfrastructure a Strategic Choice," EDUCAUSE Quarterly, no. 1 (2007), pp. 21–29.
- Ibid.
- Jacqueline Bichsel, Research Computing: The Enabling Role of Information Technology (Louisville, CO: ECAR, November 2012).
- Larry Aagesen, Goncalo Abecasis, Brian Arbic, Charles Brooks, Lee Hartmann, Eric Hetland, Oliver Kripfgans, Jason Owen-Smith, Katsuyo Thornton, and Paul Zimmerman, ARCAT report 10/27/2013[http://arc.research.umich.edu/wp-content/uploads/2013/09/ARCATreport2013.pdf] (a report from the Advanced Research Computing Advisory Team, University of Michigan).
© 2014 Thomas J. Hacker, Baijian Yang, and William Gerry McCartney