
© 2005 Andries van Dam, Sascha Becker, and Rosemary Michelle Simpson
EDUCAUSE Review, vol. 40, no. 2 (March/April 2005): 26–43.
The dream of universal access to high-quality, personalized educational content that is available both synchronously and asynchronously remains unrealized. For more than four decades, it has been said that information technology would be a key enabling technology for making this dream a reality by providing the ability to produce compelling and individualized content, the means for delivering it, and effective feedback and assessment mechanisms. Although IT has certainly had some impact, it has become a cliché to note that education is the last field to take systematic advantage of IT. There have been some notable successes of innovative software (e.g., the graphing calculator, the Geometer’s Sketchpad, and the World Wide Web as an information-storage and -delivery vehicle), but we continue to teach—and students continue to learn—in ways that are virtually unchanged since the invention of the blackboard.
There are many widely accepted reasons for the lack of dramatic improvement:
- Inadequate investment in appropriate research and development of authoring tools and new forms of content
- Inadequate investment in the creation of new dynamic and interactive content that takes proper advantage of digital hypermedia and simulation capabilities (as opposed to repurposed print content) at all educational levels and across the spectrum of disciplines
- Inadequate investment in appropriate IT deployment in schools (e.g., although PCs are available in K-12, there are too few of them, they are underpowered, and they have little content beyond traditional "drill-and-kill" computer-aided instruction, or CAI; at the postsecondary level there is more availability of computers and software, plus routine use of the Internet, but still a dearth of innovative content that leverages the power of the medium)
- Inadequate support for teacher education in IT tools and techniques and for the incorporation of IT-based content into the curriculum
- The general conservatism of educational institutions
Despite this disappointing record, we remain optimistic. The dramatic advances in hardware technology, especially during the last decade, provide extraordinary new capabilities, and the desire to "do something" to address the need for lifelong, on-demand learning is finally being widely recognized. The ubiquity and accessibility of the Internet has given rise to a new kind of learning community and environment, one that was predicted by Tim Berners-Lee in his 1995 address to the MIT/Brown Vannevar Bush Symposium1 and that John Seely Brown elaborated into the rich notion of a learning ecology in his seminal article "Growing Up Digital: How the Web Changes Work, Education, and the Ways People Learn."2 There is great hope that this emergent learning environment will in time pervade all organizations, binding learners and teachers together in informal, ever-changing, adaptive learning communities.
Here we will first recapitulate some well-known technology trends that make current platforms so exciting, and then we will briefly discuss leveraging this technology into highly desirable forms of learning. Next we will examine an IT-oriented education research agenda prepared by a consortium called the Learning Federation and will present some promising educational software experiments being conducted at Brown University. Finally we will describe an as-yet-unrealized concept called "clip models": simulation-based interoperable families of components that represent multiple levels of explanatory power and simulation fidelity designed to be assembled into systems. We make no attempt here to present a critical review of the entire field of educational software or of its impact. A variety of organizations, journals, and conferences is addressing the uses and impact of IT in education; in particular, EDUCAUSE and its Center for Applied Research (ECAR) provide a good introduction to resources and studies of IT in higher education.
Technology Trends
Exponential advances in computer architecture in the last two decades have enabled the creation of far more compelling and engaging educational software than we could have dreamed of in the Apple II days. Advances in four areas of IT will continuously raise the bar on user experiences: platform power used for computation and graphics/multimedia; networking; ubiquitous computing; and storage.
The commoditization of the necessary platforms, a trend described by Moore’s "law," is epitomized by supercomputer power and high-end graphics/multimedia capabilities in desktop and laptop computers costing less than $1,000 and even in specialized game boxes costing less than $200. Alan Kay’s Dynabook vision can at long last be realized,3 and even the personalized and ever-evolving "young lady’s illustrated primer" from Neal Stephenson’s Diamond Age will leave the realm of science fiction.4
Advances in networking enrich user experiences with ubiquitous, always-on, high-bandwidth connections. Already, gigabit networking over local area networks is a reality, and the Internet2 project is creating the core of a massively broadband global network. Wireless connectivity is widely available in both developed and underdeveloped countries and will rapidly increase in bandwidth. The commoditization of bandwidth eliminates physical distance and carrier costs as a factor in providing resources to a worldwide audience.
Ubiquitous computing environments5 have become commonplace; embedded sensors and microcomputers transform ordinary passive objects into intelligent objects that interact with each other and with us in a great diversity of form factors. Keeping pace with the hardware is ever-more sophisticated software that uses the results of artificial intelligence research in practical applications of the "smart objects."
Compelling experiences and work products alike require data storage that is reliable, fast, and inexpensive. A 1.44-megabyte floppy disk cost a few dollars in the early 1990s and couldn’t be relied on to keep data safe during a bus ride home from school; today, blank DVDs can be permanently "burnt" with 4.7 gigabytes of data for less than a dollar each, and 20-gigabyte mobile storage devices cost approximately $200, making the Library of Congress accessible anywhere. In addition to raw capacity, however, data needs that must be addressed include security, privacy, validity, and format persistence.
Despite predictions that we will hit a technological wall in the coming decade, new advances repeatedly push any such wall out into the indefinite future. For example, developments in nanotechnology and quantum computing promise new capabilities in all four areas. Indeed, one can only wish that the same exponential improvement curves that apply to hardware also applied to software and content creation. Regrettably, both these hugely important areas have shown, at most, modest improvements, and there are no signs of breakthrough technology on the horizon—only continued slow, evolutionary progress. But it is precisely because of the revolutionary improvements in hardware that we can create breakthrough experiences and content. Now is the time to mount such an effort.
IT in Education: Appropriate Role?
So, what is the appropriate role for IT in education, in the broadest sense? As always, IT’s role is to augment (not to replace) the teacher, to provide human-centered tools that encourage and support adaptability and flexibility, and to enable appropriate modes of learning (e.g., small team interaction and not just individual task performance).6 Principles such as situated, active learning (i.e., learning by doing rather than just by listening)—principles that foster interactive involvement of the learner with the educational materials—are well supported by current technology trends. However, one size does not fit all in educational software. Unless new tools allow exploration at multiple levels of detail and accommodate diverse learning styles,7 they will be just as limited as ordinary textbooks. But this is easier to say than to do: there is no collective experience in authoring at multiple levels of detail and multiple points of view. Such authoring requires the development of skills and tools of far greater power than we have experience with to date.
The most important task in the application of IT to education is to author stimulating content that is as compelling as "twitch games" or even as strategy games appear to be. New content dropped into existing curricula typically shows no improvement in outcomes; we must also redefine curricula to support learner-centered, on-demand exploration and problem-solving, and we must break down traditional disciplinary boundaries. We must also train educators to take advantage of these new capabilities. This will require massive investment, on a scale we have not encountered heretofore. This content creation, curricula adaptation, and educator training will also require a long period of experimentation, as well as tolerance for the false starts that are an inevitable part of all innovation processes. For example, whereas classical CAI was thought to hold great promise in the 1960s, its applicability turned out to be rather limited; the same held for Keller plan self-paced instruction and other innovations that are in fact now reappearing in different guises.
Content and curriculum alone are not sufficient. We must provide support for all aspects of learning, in both formal and informal education, not just in schools but in all venues, ranging from the home to the office and the factory floor—anyplace where learners gather, singly or in groups. In addition, we must provide support for all aspects of this process, including course administration (as WebCT and its competitors are doing), continuous assessment (a deep research problem), and digital rights management (still a very contentious and difficult societal, commercial, and research problem).
Returning to the topic of content, we must develop software that accommodates many different human-computer interactions, from single-user to massively collaborative multi-user. Genres must be equally diverse, from cognitive tutors such as CMU’s Pump Algebra Tutor, or PAT (http://act.psy.cmu.edu/awpt/awpt-home.html), to simulation- and rule-based interactive models (microworlds), massive multiplayer games, and robots constructed and programmed to carry out specified tasks.
Even before such adaptive, personalized content is widely available, we must also rethink learning environments—that is, envision profound structural change at all levels of education to accommodate the kind of learning the new content facilitates. Early examples of experiments in structural change include Eric Mazur’s Peer Instruction Physics (http://mazur-www.harvard.edu/education/educationmenu.php), the RPI Studio Model (http://ciue.rpi.edu/), and the Virginia Tech Math Emporium (http://www.emporium.vt.edu/). Both the RPI Studio Model and the Virginia Tech Math Emporium change not just the structure of the educational process but even the facilities required. This is just the beginning of rethinking college and university instruction from the ground up. In addition, distance learning, as embodied by the Open University (http://www.open.ac.uk/) and the University of Phoenix (http://www.phoenix.edu/), shows that non-campus-based instruction can work, although the materials used are not particularly innovative as yet. On a cautionary note, we should add that there have been many recent failures in commercial distance learning. Traditional colleges and universities with classroom/laboratory instruction will not soon be replaced, although they will certainly be augmented by newer, IT-based forms of learning.
The Computing Research Association’s "Grand Challenge 3"—"Provide a Teacher for Every Learner" (http://www.cra.org/reports/gc.systems.pdf)—describes some of the genres mentioned above, but the most important conclusion of that report, reflected in its title, is that by providing powerful tools, we offer the opportunity to rethink the relationship between teachers and learners. The appropriate use of IT will empower teachers to enhance their mentoring roles and can supplement such teacher support with peer and computer-based mentoring and tutoring to provide students with essentially full-time, on-demand, context-specific help. Building domain-specific mentoring, tutoring, and question-answering is scarcely a solved problem and will require a very significant research and development (R&D) effort.
Getting There:
Learning Federation Research Roadmaps
To better understand the issues involved and to direct a focused research investment effort, Andries van Dam helped to found a small steering group that has proposed the creation of a nonprofit, industry-led foundation, called the Learning Federation (http://www.thelearningfederation.org/), modeled on the highly successful Sematech Consortium (http://www.sematech.org/). The Learning Federation is a partnership joining companies, colleges and universities, government agencies, and private foundations whose purpose is to provide a critical mass of funding for long-term basic and applied pre-competitive research in learning science and technology. This research, to be conducted by interdisciplinary teams, is meant to lead to the development not only of next-generation authoring tools but also of exemplary curricula for both synchronous and asynchronous learning.
The Federation’s first task was to produce a Learning Science and Technology R&D Roadmap. This roadmap describes a platform-neutral research plan to stimulate the development and dissemination of next-generation learning tools, with an initial focus on postsecondary science, technology, engineering, and mathematics. The component roadmaps, which address five critical focus areas for learning science and technology R&D, were developed using expert input from companies, colleges and universities, government research facilities, and others with unique expertise during a series of specialized workshops, consultative meetings, and interviews. Each roadmap provides an assessment of the R&D needs, identifies key research questions and technical requirements, and specifies long-term goals and three-, five-, and ten-year benchmarks—the roadmap to the long-term goals. The following sections give the abstracts from the component roadmaps, along with the URLs where the full PDF files may be downloaded.
Instructional Design:
Using Games and Simulations in Learning
"Learning environments that provide learners opportunities to apply their knowledge to solve practical problems and invite exploration can lead to faster learning, greater retention, and higher levels of motivation and interest. Unfortunately, these learning strategies are rarely used today because they are difficult to implement in standard classroom environments. Expected improvements in technology have the potential to significantly reduce the cost and complexity of implementing learning-by-doing environments. The combined forces of high-powered computing, unparalleled bandwidth, and advances in software architecture are poised to make realistic gaming and simulation environments more feasible and economical. Because these tools will be increasingly available, it is important to understand appropriate contexts and methods for implementation. The challenge is to understand how the tools should be used, with whom and for what?" See (http://www.thelearningfederation.org/instructional.html).
Question Generation and Answering Systems
"Question generation is understood to play a central role in learning, because it both reflects and promotes active learning and construction of knowledge. A key challenge to researchers and practitioners alike is to find ways to facilitate inquiry by taking advantage of the benefits offered by emerging technologies. Further exploration is needed in the realm of intuitive interfaces that allow the learner to use spoken language, or coach the learner on how to ask questions, tools to enable answers to learners’ questions—including linking learners to real people, as well as the creation of intelligent systems that ask the learner questions or present problems that require major attention and conversation." See (http://www.thelearningfederation.org/question.html).
Learner Modeling and Assessment
"Assessment generates data for decisions such as what learning resources to provide individual learners and who to select or promote into particular jobs. These decisions are only as valid as the data and interpretations that are available. Ideally, every educational decision-maker, from teacher to human resource director, would have access to real-time valid data to make a decision about an individual, group, or program. There is a critical need to articulate more precisely and reach consensus on many of the theoretical underpinnings and models that drive our assessment practices." See (http://www.thelearningfederation.org/learner.html).
Building Simulations and Exploration Environments
"Research has demonstrated that simulation environments are powerful learning tools that encourage exploration by allowing learners to manipulate their learning experience and visualize results. Simulations used in academic settings can enhance lectures, supplement labs, and engage students. In the workplace, simulations are a cost-effective way to train personnel. Despite important successes in the use of simulation and synthetic environments, there are still a number of limitations to current applications and programs. The goal of this R&D effort is to make simulations and synthetic environments easier to build and incorporate into learning environments." See (http://www.thelearningfederation.org/building.html).
Integration Tools for Building
and Maintaining Advanced Learning Systems
"As specifications and standards have been developed to support web-based system directed learning systems, the means for creating interoperable and robust instructional content have emerged. However, these specifications have defined a technically complex infrastructure that is unfriendly to instructional designers. Designers should be able to focus entirely on content, the needs of students, and instructional theory and not on the mechanics of the software. A variety of authoring and integration tools are needed to make it easy to identify software resources and to combine these resources into a functioning system." See (http://www.thelearningfederation.org/integration.html).
Beginnings: Brown University Projects
Microworlds
At Brown University, partially inspired by Kay’s powerful Dynabook vision,8 we have been particularly interested in building simulation and exploration environments, often referred to as microworlds. These can be used to teach abstract concepts, such as Newton’s laws and the Nyquist limit for signal processing, and skills, such as spatial visualization and integration by parts. The combination of the Web and Java applets has resulted in a proliferation of applets across a broad range of subjects.
For the last decade, inspired by many applets on the Web, we have been developing computer graphics teaching applets called Exploratories (see Figure 1). These highly interactive, simulation-based applets are built from reusable software components and can be embedded in a Web-based hypermedia environment or used as downloadable components in a wide variety of settings. Their design builds on a geometric structure to simulate behavior. Users can control the environment and experiment with different variables through interface-exposed parameters. To date we have over fifty Exploratories in computer graphics alone (http://www.cs.brown.edu/exploratories/).
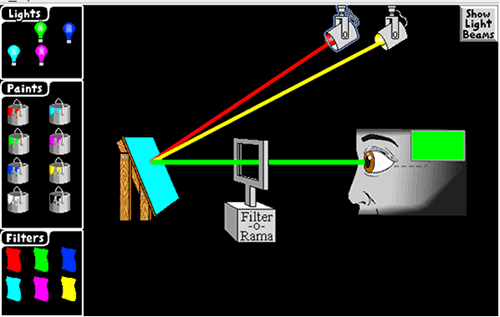
Figure 1. Exploratory on color mixing, highlighting the differences between mixing light and mixing paint
Gesture-Based Tablet PC Applications
In an increasingly ubiquitous world of iPods, digital camera cell phones, and wireless everything, the WIMP ("Windows, Icons, Menus, and Pointers") interface has been gradually augmented by post-WIMP interface techniques as mobile users experience the convergence of media and communication technologies. The laptop workhorse has been expanding its capabilities as well with the advent of the Tablet PC and its pen-based interface. Until the last decade, pen-based technology was not good or cheap enough for widespread use. Gesture recognition, handwriting recognition, and digitizer technology have significantly improved in performance and availability in the last few years; now applications can be developed and deployed at retail scope.
Just as with microworlds, the Brown computer graphics group has been experimenting with gesture-based user interfaces and applications for many years9 and is currently developing gestural interfaces for the Tablet PC. Two of these are MathPad2 and ChemPad.
MathPad2Mathematical sketching is a pen-based, modeless gestural interaction paradigm for mathematics problem-solving. Whereas it derives from the familiar pencil-and-paper process of drawing supporting diagrams to facilitate the formulation of mathematical expressions, users can also leverage their physical intuition by watching their hand-drawn diagrams animate in response to continuous or discrete parameter changes in their written formulas. Implicit associations that are inferred, either automatically or with gestural guidance, from mathematical expressions, diagram labels, and drawing elements drive the diagram animation.
The modeless nature of mathematical sketching enables users to switch freely between modifying diagrams or expressions and viewing animations. Mathematical sketching can also support computational tools for graphing, manipulating, and solving equations.
The MathPad2 mathematical sketching application currently uses MATLAB as its underlying math engine and provides a fully gestural interface for editing. Expressions can be deleted, edited, and rerecognized in a fully modeless operation (see Figure 2).
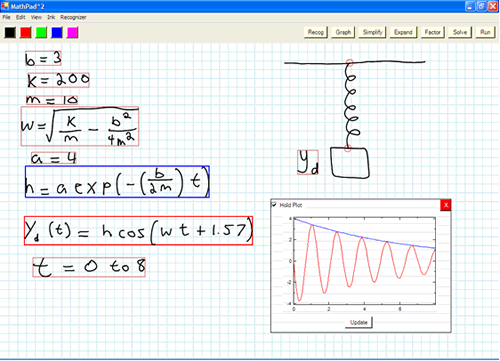
Figure 2. MathPad2 sketching interface of a mass spring system.
ChemPadOrganic chemistry is the study of the structure and function of carbon-based molecules. These molecules have complex, three-dimensional structures that determine their functions. Ideally, students would do all their thinking and drawing in three dimensions (3D), but whiteboards and paper notebooks support only 2D structures and projections of 3D and higher-dimensional structures. To compensate, organic chemists use a complicated 2D schematic notation for indicating the spatial arrangement of atoms in a molecule. With practice and insight, beginning chemists can develop the ability to look at such a 2D schematic description of a molecule and automatically construct a mental model of the 3D structure of that molecule.
Teachers of organic chemistry identify this spatial understanding as a key determinant of whether students will succeed in organic chemistry. We have been designing and developing a software project, ChemPad, whose purpose is to help organic chemistry students develop an understanding of the 3D structure of molecules and the skill of constructing a 3D mental model of a molecule that matches a 2D diagram (see Figure 3). ChemPad fosters this understanding by allowing the student to sketch a 2D diagram and then to see and manipulate the 3D model described by the diagram.
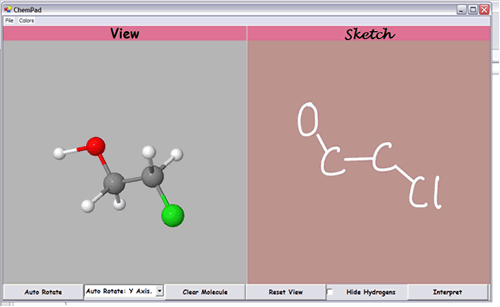
Figure 3. The ChemPad program displays an organic molecule, 2-chloro-ethanol.On the right side, the user has sketched the non-hydrogen atoms of the molecule using standard organic chemistry conventions. On the left side, the program has generated and rendered a 3D view of the molecule. The user is able to rotate the 3D representation and examine it from arbitrary points of view.
A pen-based interface is particularly appropriate for drawing organic chemistry molecules because the existing software tools in this area are difficult to learn and use, which places them out of the reach of most students. Drawing with pen and paper, though, is not entirely satisfactory; it is difficult to produce neat drawings, and it is difficult to erase and correct errors neatly. ChemPad addresses both these issues, with a simple interface that mimics drawing on paper and with a "beautify" function that "tidies up" a student’s drawing. ChemPad also provides validity-checking; many of the structures that beginning students draw do not describe physically possible molecules. Unlike paper and pencil, ChemPad can detect and indicate certain kinds of errors. One possible extension of this approach would be to add simulation capabilities so that the static ball-and-link 3D diagrams can start to approximate the actual dynamics of molecular interaction.
Limitations of Our Current Work
Although microworlds have been useful adjuncts to the undergraduate computer graphics course, they fall short of the goals for a far more ambitious vision. Microworlds and Exploratories are restricted to single concepts with a small set of parameters. However, because they are component- and parameter-based, they illustrate some of the fundamental principles that will be essential in fully functioning clip-model environments, and they open possibilities for evolving even more flexible structures. The combination of fluid and multi-POV (point of view) hypermedia information structures with component-based software architectures may provide a foundation on which we can build.
Tablet-PC-based gestural interfaces to applications are underdeveloped because the state-of-the-art in robust user-independent gesture recognition is still primitive. Furthermore, gesture sets are anything but self-disclosing, and they take considerable time to learn. Finally, our experiments thus far are essentially single-user in their orientation and don’t facilitate a collaborative, team-based approach to learning. The next section addresses some of the issues involved in designing software that can be adapted to multiple needs, users, and levels of detail.
Clip Models:
A Proposal for Next-Generation
Educational and Research Software
Over forty years ago, Jerome Bruner proposed a radically new theory of education: "Any subject can be taught effectively in some intellectually honest form to any child at any stage of development."10 Although many people have disputed the more extreme claims attached to that hypothesis, it is an admirable goal. One way to implement it is through the "spiral approach to learning," common to formal education, in which a learner encounters a topic multiple times throughout his or her education, each time at an increasing level of sophistication. Furthermore, at any stage, the learner should be able to mix and match educational modules at different levels of sophistication within the same general topic area. Simpler modules can offer overviews of a subject for review or provide context when the intent is to go more deeply into related topics.
The kinds of modules we are most interested in here are simulation- or rule-based modules that help create explorable models of subsystems, which can be linked into increasingly higher-level subsystems. Such modules can help simulate most aspects and components of the natural and man-made worlds. We will focus here on simulating subsystems of the human body at all levels, from the molecular to the cellular to the gross anatomical. Each subsystem of the human body must then be simulated at a level appropriate to the (educational) purpose. There is not just a single model/simulation for each component of the system (e.g., the heart or lungs) but a family of models/simulations varying in explanatory power and simulation fidelity—not to mention, ideally, in the learning style it is to match. Furthermore, since subsystems interact with each other, the models and their underlying simulations must be able to interoperate. We summarize the properties of these types of models with the term "clip models": simulation-based families of components that represent multiple levels of explanatory power and simulation fidelity designed to interoperate and to be assembled into systems. In particular, unlike clip art, which represents only images, clip models emphasize behavior, interaction/exploration, and interoperability.
This concept of mix-and-match, multi-LOD (level of detail) models poses huge challenges to would-be implementers. The inherent challenges of building multi-resolution, multi-view, multi-complexity interoperating simulations have not yet been confronted because most simulation efforts have been standalone projects. In the same way, repositories of learning objects have stored only objects at a single level of explanatory power, and component frameworks in use by software developers have not been designed with the complexity of interoperation between components at different levels of detail in mind.
A Biological Scenario
The concept of clip models can best be explained with an illustration. The details don’t really matter; the important thing is to note the complexity of the relationships between simulated components and the potential applications of this family of simulations for education and research.
Figures 4, 5, and 6 are an abstract representation of how the heart and vascular systems interact with other systems used by the human body to regulate oxygenation—that is, to make sure that we have enough oxygen in our blood, and not too much. This homeostasis, crucial for maintaining life, relies on several interconnected mechanisms, including functions of the kidney, the heart, the brain, the lungs, and chemoreceptors located throughout the body.
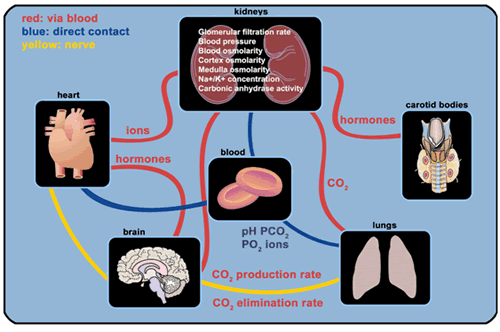
Figure 4. Elements in the system for control of oxygenation in the human body
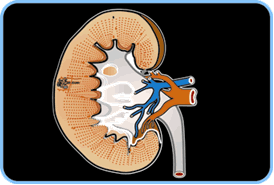
Figure 5. A more detailed view of the kidney, a cross section with some of the internal structures
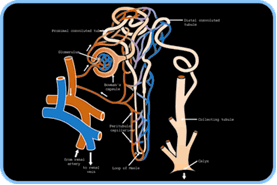
Figure 6. A more detailed view of a nephron, the microscopic functional unit of the kidney
All of these systems are connected by the blood, and each of them plays a slightly different role. The blood’s behavior as an oxygen carrier is determined by macro- and microscopic factors, from the fraction of blood composed of red blood cells, visible to the human eye in a test tube, to the electrostatic attraction between oxygen and hemoglobin molecules at a scale too fine to be seen with any microscope. Hormones that regulate the actions of the kidney, the heart, and the lungs are generated by the kidney, the brain, the lungs, and the endocrine system, including endocrine glands located in or near the brain.
The kidneys monitor and correct various characteristics of the blood. To understand their function, we must first perceive them at a coarse level as organs that produce urine by filtering the blood. At this coarse scale, we must understand only that blood is delivered to and accepted from the kidneys by large blood vessels and that the kidneys produce urine; this level of understanding is appropriate for an elementary school student. To understand how the kidneys perform this function, a more advanced learner must examine their structure at a much finer scale, the scale of the nephron, of which each kidney has millions.
The heart rate and the volume of blood ejected per heartbeat control the rate of distribution of oxygen to the body; these factors are jointly controlled by the brain and by the heart itself. The lungs’ respiration rate and inhalation volume are controlled by the brain via nerves, but the oxygen absorption and the carbon dioxide elimination rate are also determined by the concentration of these gases in the blood. The carotid bodies, in the neck, monitor the oxygen concentration in the blood and inform the brain when more oxygen is needed. The brain then issues hormones and neural signals, carried by the blood and the nervous system to other organs, which adjust their operation to correct the problems.
In our simplified illustration, we show three levels of detail for examining the roles of the heart and the kidneys in homeostatic oxygenation. Figure 5 illustrates more detail of the kidney, a cross section with some of the internal structures. Figure 6 depicts a single nephron in the kidney. A learner can dynamically select which level to examine and may explore different levels at different times, depending on need. Clearly, clip-model exploration by itself may not suffice in an educational context. We must not only embed it in explanatory context (e.g., a hypermedia document) and organizational structure (e.g., a self-paced course) but also enrich it with some type of problem-solving and/or construction activity and continuous feedback and assessment.
Clip-Model Implications
The interconnected mechanisms in the example above, along with the fundamental interconnectedness of system components in all disciplines, cannot all be studied or understood at once, nor can they be understood with purely linear thought. The learner’s exploratory process naturally follows the interconnected web of causality, but linear or hierarchical organizations (such as those in most software data sources and all textbooks) force the learner into an artificially linearized exploration. Linearization discourages the cross-disciplinary insights that fuel deep understanding, since it encourages compartmentalized rote knowledge.
As noted above, the varied needs of audiences at many different levels of sophistication preclude a one-to-one mapping between a given concept (such as the circulation of blood through the cardiovascular system) and a single clip model. Thus, instructional designers must think not in terms of creating a single clip model for a given topic but in terms of creating one or more components in a family of interrelated clip models that cover a broad range of explanations and their representations. These models must correctly reflect the ontology and semantics of the subject matter at each point along the multiple axes of age, knowledge level, task, and individual learning. We must also accommodate the variety of learning environments in which such clip models will be presented. These innovative and, by their nature, emergent learning environments must be made available online and on-site, in synchronous and asynchronous and in virtual and real classrooms, servicing both single on-demand learners and collaborative learners, either in impromptu virtual study groups or in formats yet to be defined. Another dimension we need to explore more deeply is team collaboration. Clearly, these requirements present a huge challenge for instructional design and learning technology.
The variety of pedagogical needs that clip models must satisfy is a complicating factor that makes their design immensely harder than that of ordinary components in standard software engineering. A potential approach to thinking about the problem may be to use an extension of the MVC (Model-View-Controller) paradigm of object-oriented programming to describe the necessary interrelationships between these different concept representations. Each concept or real-world object must be represented by a family of models (e.g., the heart as a pump, the heart as a muscle, the heart as an organ in the chest cavity), with widely different degrees of sophistication. Each model supports multiple views (e.g., simplified 3D models, realistic 3D models, 2D schematics, the sound heard through a stethoscope) and, for each view, multiple controllers that may present a learner-chosen UI (user interface) style. Multiple models that must interact, regardless of level of detail and simulation fidelity, geometrically complicate the single-model paradigm of classic MVC.
Challenges
This intersection of simulation science, software engineering, ontology (formal naming scheme) building, instructional design, and user interface design forms the technological aspect of this complex problem. In addition to the technological challenges, there are interdisciplinary organizational challenges: building clip models is essentially a new design discipline that requires collaborative teams of experts from cognitive science, social sciences, arts, design, story-telling professions, information structure design, and instructional design—working with teachers, domain experts, simulation scientists, and computer scientists. We can identify challenges for ontological engineering, simulation science, software engineering, and educational design.
As a prerequisite to interoperation, simulation elements must agree on the ontology of the conceptual realm they represent. Without a shared ontology or mappings between related ontologies, two simulation components cannot interoperate if they disagree on the point in the nephron at which the "filtrate" becomes "urine" or the names for the lobes of the liver. Furthermore, the ontology must encompass not just (geometric) structure (anatomy, in the case of biological systems) but also behavior (biochemical, electrochemical, biomechanical, etc.), a largely untackled problem, at least for biology. As an additional complication, when you have a single author or a small team of authors writing a single book targeted at a single audience, the domain specification as seen in the definition and relationships of concepts and terms is an important but manageable task. When you expand the context as described above, the situation becomes orders of magnitude more complex. Who will define the master ontology? How will other classification schemes and vocabularies build a correspondence map? Some sort of collaborative approach to ontological engineering will have to be used in order to build an ontology that is acceptable to many members of a given field.
Simulation science does not have a sufficiently flexible framework for wiring together components of a simulation from various providers that were not designed to interoperate from the beginning. How to connect simulations from different problem domains for the same subsystem is still a difficult problem. For example, simulating the heart’s operation biochemically, electrochemically, and with computational fluid dynamics, while dealing with flexible (nonrigid) and time-varying geometry and both normal and abnormal behavior, is still a daunting problem. Even with a standard vocabulary, adaptive multi-resolution simulations will be even harder to interoperate; how can they determine at what level of detail to share information? If we are running interactive simulations, should we allow algorithms to run with graceful degradation in order to meet time requirements? What is the nature of such approximations? How can the valid operating ranges of particular simulations be determined? How can the simulations report when they venture beyond those ranges? If these simulations are to be used in real science, as we hope, they must have a mechanism for comparing them with experimental results and for validating their calculations. How can a researcher compare predictions made by a Stanford heart model and by a Harvard heart model? How will a kidney model created by nephrologists at Johns Hopkins share data with a heart model from Stanford or a lungs model from Caltech not purposely designed to interoperate? How can a seventh-grade teacher in Nebraska use a fourth-grade teacher’s set of human anatomy clip models as the basis for a more detailed model of the circulatory system?
The software engineering challenges range from the commercial and social difficulties of persuading scientists to work within a common model to the software design characteristics that will enable flexibility at all levels. Just as object-oriented programming is a vast improvement in the power of abstraction compared to assembly language, so must the clip-model framework design be to today’s component frameworks; the challenges are simply too great to be addressed by incremental advances. A clip-model framework must address various questions. How can simulations ensure that they get the data they need, in the format they need, regardless of the level of fidelity at which connected clip models are running their simulation? For example, how will a heart model cope with changing stiffness in the valves if the valve model is not designed to adjust to stenosis? What protocols will keep all the simulation components synchronized in time, even if one runs in real time and another takes a day to compute a single time-step? Who will maintain the repository of code? Who will control the standards? How can interoperability be preserved when some components are proprietary?
The educational design challenges of our vision are the same problems facing today’s educational software designers. How can teachers, learners, and scientists find the components that best meet their needs? How does a student figure out that he or she is an auditory learner if the student is bombarded with visual materials? How can users evaluate the reliability, correctness, bias, and trustworthiness of authors of the components?
Progress So Far
Our field is more prepared to address this challenge today than we were twenty years ago. Software engineers used to joke and complain about rewriting a linked list, a common data structure, in every new language, project, and environment. Since then, library standardization (especially the C++ Standard Library, the Standard Template Library, Microsoft .NET, and Java’s extensive built-in libraries) has made reusable data structures available to almost any software project. Reusable component libraries have advanced to include algorithms (generic programming in C++), user interface elements (Windows Forms, Java Swing), and structured data (XML). Our proposal for clip models follows this trend of abstraction and reuse. Although none of the efforts below address the full generality of our clip-model idea, there are a number of projects that are important stepping-stones toward our goals.
Various groups are working to build learning object repositories (http://elearning.utsa.edu/guides/LO-repositories.htm)—for example, the ARIADNE Foundation (http://www.ariadne-eu.org/) and MERLOT (http://www.merlot.org/Home.po)—and to develop standards and reference models for learning objects—for example, SCORM (http://www.adlnet.org/index.cfm?fuseaction=scormabt) and IEEE’s WG12: Learning Object Metadata (http://ltsc.ieee.org/wg12/). Several efforts have begun to address some of the simulation science challenges identified above. The Center for Component Technology for Terascale Simulation Software is designing a Common Component Architecture (http://www.cca-forum.org/) as part of a program of the U.S. Department of Energy (DOE) Office of Science (SC). The Knowledge Web community is now starting to tackle the problem of identifying and encoding domain-specific ontologies for the Web. Clyde W. Holsapple and K. D. Joshi describe a collaborative approach to designing an ontology; the approach begins with independent ontological proposals from several authors and incorporates input from many contributors.11 At the University of Washington, the Structural Informatics Group has been working on the Digital Anatomist Foundational Model of Anatomy (FMA), an ambitious anatomical ontology: "The FMA is a domain ontology that represents a coherent body of explicit declarative knowledge about human anatomy" (http://sig.biostr.washington.edu/projects/fm/AboutFM.html). The ambitious Digital Human Project (http://www.fas.org/dh/index.html), which uses the FMA ontologies, is intended to incorporate all biologically relevant systems at all time and scale dimensions. They range from 10-14 sec chemical reactions to 109 sec lifetimes and perhaps 1012 for ecosystems, and from 10-9 meter chemical structures to meter-scale humans. The work thus far has focused on a series of scattered projects around the world, including the CellML (http://www.cellml.org/public/about/what_is_cellml.html) and other work at the University of Aukland. In the United States, the NIH (National Institutes of Health) (http://www.nih.gov/) has created an interagency group, is planning another meeting in 2005, and has started a number of bioinformatic centers that should help, while DARPA (Defense Advanced Research Projects Agency) has charged ahead with the Virtual Soldier Program (http://www.darpa.mil/dso/thrust/biosci/virtualsoldier.htm) and the BioSPICE program (https://community.biospice.org/).
Conclusion
Rethinking learning and education, in all of their dimensions, to successfully address the needs in this century is an overwhelmingly large and complex research and implementation agenda that will require a multi-decade—indeed, never-ending—level of effort on the part of all those involved in creating and delivering educational content. Nonetheless, a start must be made, as a national—indeed, global—imperative.
The start we’re proposing here (the Learning Federation’s R&D roadmaps) is another first step in the quest to build next-generation educational content and tools. This research agenda is meant to lead to the development not only of next-generation authoring tools and content but also of exemplary curricula in the broadest sense. The research agenda is predicated on our belief that "hardware will take care of itself" because of commoditization driven by market forces. Educational software R&D, on the other hand, thus far has insufficient commercial appeal and must therefore be considered a strategic investment by funding agencies and companies. Industry and government are certainly investing in computer-based training; much can be learned from their successful efforts.
To return to our biology example, we believe that the creation of families of interoperable clip models that will describe the human body as a system of interconnected biological components at all levels—from the molecular to the gross anatomical—will provide an unprecedented learning resource. Even though the creation of such families of clip models in a variety of disciplines will necessitate the integration of work from thousands of contributors over decades, even a beginning but very ambitious and comprehensive effort, such as the Digital Human Project, at building biological system components will have a payoff. We should not be daunted by the sheer magnitude of the task but should make steady progress along a clearly articulated path.
Furthermore, clip models are not, by themselves, the answer: there is no magic bullet, no single style of educational content that can encompass the enormously diverse set of requirements for this agenda. Creating high-quality next-generation educational content, across all disciplines and at all levels, will require a Grand Challenge effort on a scale such as the Manhattan Project, the Man on the Moon (Apollo) Project, and the Human Genome Project. The U.S., European, and several Asian economies certainly have both the ability and the need to cultivate the will to invest the same amount in creating exemplar interactive courses as they do in videogames and special-effects movies. Indeed, the U.S. Department of Defense is making significant modern IT-based investments for its training needs, mostly notably in "America’s Army" (http://www.americasarmy.com/) and the funding of institutes such as the USC Institute for Creative Technologies (http://www.ict.usc.edu/). We cannot afford to have the civilian sector left behind. The Learning Federation has made a start in working with the government with the DOIT (Digital Opportunity Investment Trust) report (http://www.digitalpromise.org/), which articulates a potential funding mechanism based on spectrum sales.
The payoff from the huge investment of time, energy, and money cannot be overstated. Beyond education, the clip-model architecture will help advance science itself. The architecture will enable the "development" aspect of R&D to rapidly integrate advances in basic research. The coming avalanche of data in genomics and proteomics will require massively interconnected simulation systems; otherwise, how will the identification of a gene in Japan link to a class of pharmaceutical candidates for a rare disease being researched in Switzerland? Information sharing must be augmented by model sharing as an intrinsic part of the research process if connections are to be drawn between advances in different specialized fields—not sharing simply by publishing papers in research journals but by publishing information as software objects that can be used immediately (subject to accommodating the relevant IP and commercialization issues) in other research projects. We cannot predict the insights that will be revealed by happy accident when two or three unrelated strands of knowledge are unified in an integrated model, but we can eagerly anticipate the leverage that will be gained from the synergy.
We gratefully acknowledge the support of our sponsors: NSF and Sun Microsystems, which supported the Exploratories Project led by Anne Morgan Spalter; NSF and Microsoft, which support the work on MathPad2 led by Joseph LaViola; and Hewlett Packard, which provided twenty Tablet PCs to enable us to conduct a user study of ChemPad, led by Dana Tenneson, in an organic chemistry class. In addition we thank Janet Bruesselbach, the clip-model illustrator, and our four reviewers: Henry Kelly and Randy Hinrichs (who also are co-founders of the Learning Federation), Anne Morgan Spalter, and Debbie van Dam.
1. Rosemary Simpson, Allen Renear, Elli Mylonas, and Andries van Dam, "50 Years after ‘As We May Think’: The Brown/MIT Vannevar Bush Symposium," ACM Interactions, vol. 3, no. 2 (March 1996): 47–67.
2. John Seely Brown, "Growing Up Digital: How the Web Changes Work, Education, and the Ways People Learn," Change, March/April 2000, http://www.aahe.org/change/digital.pdf.
3. Alan Kay and Adele Goldberg, "Personal Dynamic Media," IEEE Computer, vol. 10, no. 3 (March 1977): 31–41.
4. Neal Stephenson, The Diamond Age; or, Young Lady’s Illustrated Primer (New York: Bantam Books, 1995).
5. See Mark Weiser’s Web site: http://www.ubiq.com/hypertext/weiser/weiser.html.
6. We know all too little about effective group learning using digital media. A lot could be learned, for example, from studying the kind of informal learning ecology that typifies massive multiplayer games, such as "The Sims," "EverQuest," and "Asheron’s Call."
7. Howard Gardner, Frames of Mind: The Theory of Multiple Intelligences, 10th anniversary ed. (New York: Basic Books, 1993).
8. Kay and Goldberg, "Personal Dynamic Media."
9. Robert C. Zeleznik, Kenneth P. Herndon, and John F. Hughes, "SKETCH: An Interface for Sketching 3D Scenes," Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques (New York: ACM Press, 1996), 163–70.
10. Jerome S. Bruner, The Process of Education (Cambridge: Harvard University Press, 1960), 33.
11. Clyde W. Holsapple and K. D. Joshi, "A Collaborative Approach to Ontology Design," Communications of the ACM, vol. 45, no. 2 (February 2002): 42–47.