
Key Takeaways
-
The current learning data ecosystem is a chaotic, increasingly complex jumble that is producing vast amounts of usage data that are poorly understood and poorly utilized.
-
To accelerate the move to the Next Generation Digital Learning Environment, we need widespread adoption of learning data standards across institutions.
-
Early proof-of-concept implementations by two universities illustrate the current maturity of learning data standards and how they address real-world problems.
-
To achieve standards adoption at a broader scale — and reap the considerable benefits NGDLE promises — key challenges must be understood and addressed.
As she walks back to her dorm, Emily Hattiangadi checks her phone and chats with a classmate about the group assignment for their digital humanities history course. Earlier, she had gone to the library to do research for a paper; she then participated in a lecture where, alongside 800 classmates, she answered polling questions using a clicker she purchased online and uses for at least two other courses.
Back at her dorm Emily logs into the learning management system, reads a required article linked from a library database, responds to a discussion post in a third-party tool, and then logs into a separate system to watch the first part of a lecture she missed.
She is anxious about her computer science grade, so she logs into yet another system to check, for the third time that day, whether the exams have been graded. They haven't. A few minutes later, she receives a group text from the course's teaching assistant letting her know that the graded exams will be available before noon the next day. She goes to bed, without a thought about all the data related to her learning behaviors that she has generated that day.
Countless variations of this scene play out every day across college campuses. Learners and instructors use multiple systems and applications — some licensed by the institution, and some free tools that faculty and students use without a written agreement between the supplier and the campus. All of them collect data about learners.
The current digital learning ecosystem is a big, uneven jumble that works in part, but is increasing in complexity, lacks consistency in contract and vendor management, has less-than-rigorous data governance oversight and controls, uses a mix of identity and access management approaches, and produces increasing amounts of usage data "exhaust" that is not well understood, managed, or analyzed.
The Next Generation Digital Learning Environment (NGDLE) is a broad response to the challenges of this evolving and complex digital learning environment. As EDUCAUSE describes it, the NGDLE is a framework whose "principal functional domains are interoperability; personalization; analytics, advising, and learning assessment; collaboration; and accessibility and universal design."1
Standardization Overview
To accelerate the transition to NGDLE and achieve its vision of seamless integration and interoperability, we must further the adoption of learning data standards across the educational technology landscape. The future growth of the personalization, analytics, advising, and learning assessment domains in particular depend on efficiently leveraging the massive quantities of underlying user activity data generated by the myriad tools our instructors and students use.
The Importance of Scale
Unfortunately, NGDLE's benefits are difficult to achieve at scale, especially if the burden and cost of standardizing and aggregating learning data are handled individually by each institution. Turning the task over solely to suppliers with their own proprietary tools and processes entails a real risk of vendor lock-in. Custom solutions, developed by either a school's local IT shop or a supplier, can also raise barriers to cross-institutional data analysis, potentially hindering learning science research.
In practical terms, the goal is that, regardless of whether Emily posts in a third-party discussion tool for one class or in the LMS's native discussion forum for another, the event or activity data she generates is packaged and described in the same format with the same vocabulary. In other words, for the sake of analysis, a discussion post is a discussion post is a discussion post.
To underscore the importance of standardization, let's take a closer look at another example: the learning activity data generated in a lecture capture system. Most lecture capture systems let users play, stop, and rewind; some have more advanced features such as share, annotate, and play at double speed. When these systems capture user interactions as event data in log files or databases, they might label a student's "click" to start a video as "play" or "playInit" or "startVid" or any number of cryptic event descriptors.
Aggregating multiple descriptors that represent the same discrete events across many systems can be a tedious, complex, and error-prone activity. With a standards-based approach, however, we can describe learner activities so that the learning activity data from across disparate applications can be aggregated, combined, and analyzed.
The Current Landscape
Two learning data interoperability specifications are currently available to instrument applications — that is, to modify an application so that it emits user event data in a standard-defined format or profile.
The two standards are xAPI, supported by the Advanced Distributed Learning (ADL) initiative, and Caliper, supported by the IMS Global Consortium.2 While the two organizations consider their standards to be complementary, their coexistence may make it harder for suppliers and institutions to decide whether to invest in one or the other or both. The good news is that ADL and IMS are working together, which, according to IMS CEO Rob Abel, will lead to convergence.
xAPI is the older of the two specifications. In its 2016 year-end report [https://www.adlnet.gov/xapi-year-in-review], ADL cited mutual efforts to align xAPI and Caliper. The report also acknowledged a growing shift in attention toward standardized vocabularies and profiles to describe learning events.
Example Implementations
As we outline here, the University of Michigan and the University of California, Berkeley, are focusing our efforts on adopting Caliper because it emphasizes a defined information model for a range of learning activities.3 The model describes learner activity through a curated, controlled vocabulary and provides specific contextual detail. Figure 1 shows an example outlining the structure of a simple Caliper event statement of a video interaction.4
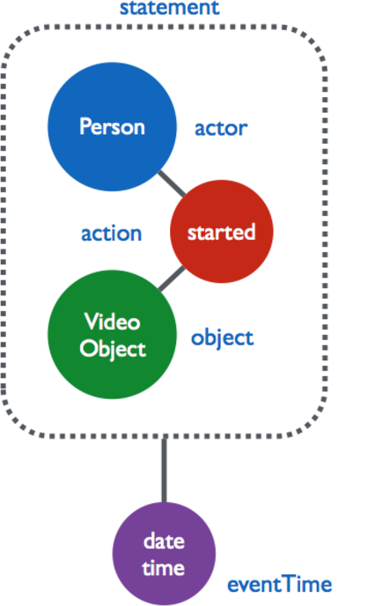
Michigan and UC Berkeley have several early Caliper-based proof-of-concept implementations that illustrate the current level of maturity of learning data standards and how they can be used to solve real-world problems. Chris Vento, the former co-chair of the IMS Global Caliper Workgroup, documented other proof of concept use cases [http://www.ltiapps.org/sites/default/files/CaliperPOCBriefs.pdf] involving partnerships between institutions and suppliers.
UC Berkeley
UC Berkeley's approach to learning data and our work with the Caliper standard began as we moved to a software-as-a-service (SaaS) learning management system (LMS) and began building our own LTI tools to augment its capabilities. We recognized the importance of maintaining access and ownership over these data and the need for the data to be standardized across our multiple systems and tools.
We took a foundational approach to this problem by developing a learning record store (LRS), a cloud-based learning analytics processing infrastructure built around the xAPI and Caliper specifications. Its central component is a database specifically designed to hold xAPI and/or Caliper formatted learning data from any application.
The LRS currently ingests learning events, such as logins and submitted assignments, sent in real time by the Canvas LMS in Caliper format (currently this Canvas data feed is in beta). These events will be made available to other systems and applications once the Canvas Caliper feed moves into production later in summer 2017.
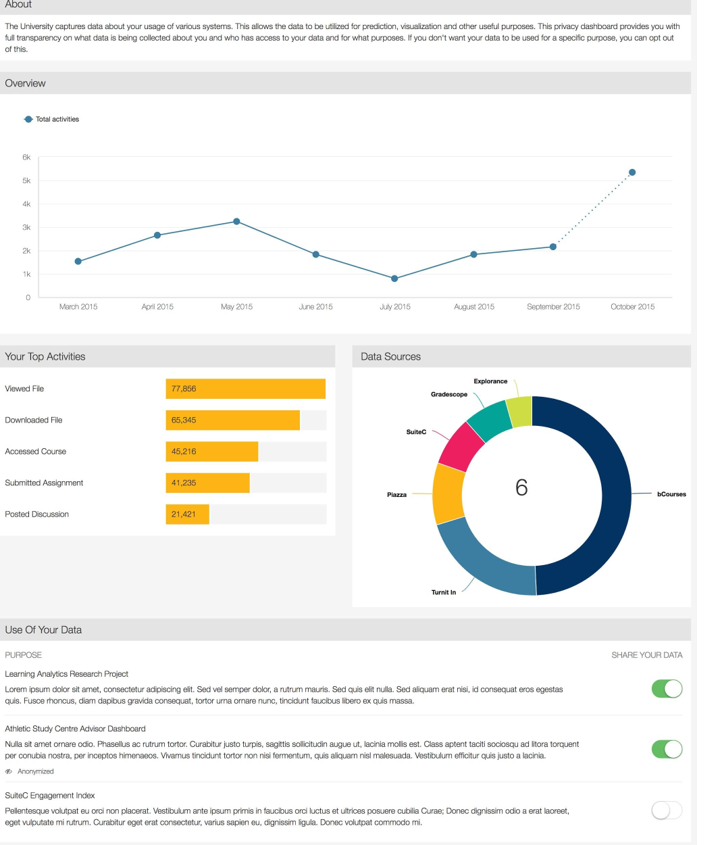
The LRS's stored Caliper learning events data are visualized in a privacy dashboard in the Canvas LMS (figure 2). This is a fully functional demo, not yet in production. The privacy dashboard discloses to students the learning data being captured about them and how it is being used (such as for research and/or early warning tools).
University of Michigan
For the past several years the University of Michigan has been a leading higher education institution in the field of learning analytics. As faculty and administrator interest has increased, the Information Technology Division at Michigan has moved to develop enabling capabilities and infrastructure for learning analytics, including chairing the Caliper working group and applying the nascent standard to existing learning applications.
To establish a proof-of-concept learning analytics infrastructure, Michigan chose the Caliper standard to represent events generated by a homegrown lecture capture service from its College of Engineering.
We chose a subset of user interactions for capture, including new session start, start viewing a lecture, pause, resume, and end viewing a lecture. This information will allow instructors to see which parts of their lectures are watched or rewatched most often, suggesting which parts of the lecture are most helpful or need additional explanation. Our next step is to develop a way to analyze and visualize the lecture capture service's aggregated event data.
We also used Caliper to instrument our Problem Roulette application, which provides students with randomized questions from prior-term course exams and problem sets. The Caliper assessment event data is fed to the open-source OpenLRS. Once stored in the LRS, the data is used to feed visualizations of student activity.
The Challenges
Although these early implementations and collaborations between suppliers and institutions show promise and good intent, significant challenges must be overcome before the full promise of a standards-based approach to learning data interoperability is fulfilled.
The barriers and difficulties are spread across the various players, including the standards organizations, suppliers, and institutions. These encompass technical, cultural, and change-management issues. Some of these issues are upstream from standards adoption per se, but they all point to challenges entailed in the prospective wider uses of learning data. A few of the key challenges follow.
Lengthy Implementation Process
Defining, developing, and supporting implementation of a standard over successive iterations is inevitably a lengthy process that creates multiple tensions. This may be especially true when the ambition is to develop a comprehensive vocabulary and set of profiles to describe the full range of learning activities.
At any point when the current specification does not adapt quickly enough or adequately meet supplier or institutional requirements, there's a temptation to either move forward without adhering to the standard or to rely on a shallow implementation (xAPI and Caliper allow implementers to define key elements of a profile for themselves). While the latter is preferable to ignoring the standard altogether, it does create potential conflicts in the data when the standard eventually matures to cover those use case gaps.
Researcher Resistance
Learning science researchers began processing learning data for their insights long before the word interoperability was uttered; as a result, they often "just want the data." They are accustomed to normalizing the data themselves to meet their research needs, and they can be skeptical of efforts to create large-scale semantic frameworks or ontologies. While this approach may be sufficient to support a research agenda, it will not scale to operational applications of learning analytics.
Tool (and Data) Diversity
In the blended learning environment, instructor use of core online learning tools such as Gradebooks, Assignments, and Syllabus remains haphazard, resulting in data that also lacks consistency and comprehensiveness. This reduces the data's value for researchers and limits its utility for other services, making it impossible, for example, to pull a complete list of assignments to reliably populate student calendars. This calls into question the broader interoperability investment.
Institutional Issues
Many of the institutions that most need the benefits of learning data interoperability — including those focused on retention, time-to-degree, and other student success metrics — may lack the technical capabilities and financial resources to directly engage in and drive the development of the required standards. Further, most institutions have yet to develop the principles, policies, and practices to create appropriate frameworks around learning data ownership, access, use, and efficacy. This often leads to paralysis on using the data to further institutional goals and support student engagement and success.
Vendor Cooperation
Another challenge has been the slow adoption rate for data interoperability standards among vendors. Several factors could be contributing to this issue. First, because vendors need to get their products to market quickly, they may omit features perceived as non-vital, including data interoperability. A more cynical view is that vendors may be intentionally undermining data interoperability because they may rely on a business model that calls for the downstream monetization of the usage data — or, given the data that vendors hold hostage, they might believe they can sell their customers new products, such as data warehousing, analytics tools and processes, and dashboards.
Second, because the learning analytics field is still forming, vendors might be afraid of making too-early investments in this rapidly changing market.
Finally, institutions have not yet joined voices to demand that vendors offer data interoperability support. Are event data truly an intrinsic part of learning applications? Do institutions treat data interoperability as a competitive advantage, or is it merely a nice-to-have item during the request for proposals and selection processes? Although there has been some consortial activity (such as in the University of California system and the Big Ten Academic Alliance), it has to date mostly focused on information sharing. A full-fledged multi-institutional collaboration aimed at solving shared data interoperability has yet to fully emerge, although the Unizin consortium is moving in this direction.
The Good News
What's encouraging in all of this is that the demand for insights around learning processes and student success is spreading to larger, more varied audiences. While many IT leaders can already see the sustainability barriers emerging as the NGDLE future appears on the horizon, they are also positioned to start meeting these complex challenges.
To see what the future might look like in the NGDLE world driven by interoperability and meaningful data exchange, we return to our earlier scenario:
Emily Hattiangadi logs into her learning portal from her phone. She receives a detailed report of her learning activities in all of her courses, along with a personalized message outlining the individualized goals she defined for the semester and her current trajectory in meeting them.
She has opted to allow her advisor to receive updates on her progress this semester; not all of her classmates chose to do this, but she wanted to check out the new advising-alert support tool.
Emily sees that she hasn't spent as much time on her history required readings as she had planned, but that she has spent more time in the engineering design lab. She is pleased with her progress on the final project. Her latest computer science quiz has been graded, and the TA has requested a meeting with her to review one of the more difficult concepts she is struggling with. She sets up the appointment, then goes to bed feeling like she has a handle on her next steps for the coming week.
The Call to Action
It is important to recognize that not all contributions to the standards process need be financial or technical; engagement can come from the full spectrum of educational institutions and commercial organizations. Among the actions institutions can take to help advance data interoperability standards are the following:
- Start talking! The most important thing you can do is educate your campus about the use of learning data and its implications for both student success and privacy concerns.
- Ask for standardized data. Ensure that contract language for learning applications includes clear requirements for data access and maintains institutional ownership of all usage data related to the service. Include appropriate language in procurement efforts that clearly indicates a preference for open data interoperability standards.
- Engage with your vendors. Make sure your vendors have a clear understanding of the competitive need to adopt and maintain open application and data integration standards. Vendor commitment may ebb and flow in this area — particularly as they seek new revenue streams — so it is important to maintain a clear and consistent demand message.
- Use standards. If you have significant investment in homegrown learning applications, implement the standards in your own work.
- Get involved. Consider engaging directly with the IMS Global Caliper Working Group to do profile development where your institution has expertise in specific learning activities or has technical skills to offer to help write specifications and supporting code.
Notes
- Malcolm Brown, Joanne Dehoney, and Nancy Millchap, The Next Generation Digital Learning Environment. A Report on Research, EDUCAUSE Learning Initiative, April 27, 2015.
- Learning Measurement for Analytics, white paper, IMS Global Learning Consortium, 2013.
- "7 Things You Should Know About Caliper," EDUCAUSE Learning Initiative, March 2016.
- Anthony Whyte, "Overcoming Big Data Challenges: IMS Caliper Analytics, Linked Data & JSON-LD," EDUCAUSE Review, December 27, 2016.
Jenn Stringer is associate CIO for Academic Engagement, University of California, Berkeley.
Sean DeMonner is executive director, Teaching & Learning, Information Technology Services, University of Michigan.
Oliver Heyer is associate director. Academic Technology Strategy, Educational Technology Services, University of California, Berkeley.
© 2017 Jenn Stringer, Sean DeMonner, and Oliver Heyer. The text of this EDUCAUSE Review article is licensed under the Creative Commons BY-NC-ND 4.0 license.