
Key Takeaways
- Open educational resources made a dramatic appearance with the 2002 debut of MIT's Open Courseware initiative.
- In the roughly 10 years since, OERs have not noticeably disrupted the traditional business model of higher education or affected daily teaching approaches at most institutions.
- Four major hurdles seem the likeliest hindrances to adoption of OERs: discoverability, quality control, bridging the last mile, and acquisition.
- OERs could unify and advance the essentially disconnected developments in digital textbooks and MOOCs by establishing a global enterprise learning content management system.
When MIT first announced its Open Courseware (OCW) initiative in October 2002, it shook the business model of traditional higher education institutions that had established "virtual universities" in an attempt to sell their brand and their educational resources worldwide. With OCW, MIT sent a signal: we don't sell learning resources, we sell certification of learning; learning resources do not have much intrinsic monetary value, but a degree does. This was arguably the first disruption of the higher education market in decades, marking the birth of the open educational resource (OER).
Fast-forward to October 2012: OERs have failed to significantly affect the day-to-day teaching of the vast majority of higher education institutions. Traditional textbooks and readings still dominate most teaching venues even though essentially all students are online: Course management systems are used only for the dissemination of syllabi, class notes, general communications, and as a grade book. OERs are out there…somewhere. Why aren't they on campus?
Adoption Hurdles
Why do the vast majority of higher education venues still depend on expensive paper texts, while most of the world's knowledge is available for free online? Why do educators not embrace the plethora of open digital educational libraries and repositories? I suspect four major hurdles to adoption.
Hurdle 1: Discoverability
While modern search engines generally do a good job finding appropriate content to answer specific questions, they are ill suited to find educational content that builds on prerequisite knowledge and takes the learner the next step toward mastery of a certain concept. This is why most digital libraries and repositories prefer to maintain their own cataloging data ("metadata") and why attempts were made to standardize metadata specifically for educational content (e.g., Dublin Core). However, these catalogs are frequently incomplete; populated by automated harvesting processes without regard to educational context; or, even worse, crippled by entries that are wrong. While diligence and investment in catalog maintenance could remedy those shortcomings, a more systemic problem is the absence of sequencing data; the lack of defined taxonomies and association rules makes it unclear which resources build on which other resources.
Many of the repositories, even inside of unified efforts like the Open Courseware Consortium, remain disconnected from each other. Even if repositories are nominally connected through federated search, as in the National Science Digital Library, this frequently means finding the least common denominator of the available metadata. The resulting search results are frequently no better than a search on the open web — regrettable, since these projects house excellent content resources.
Particularly for OERs, the current type of static metadata is not a good fit: authors of OERs are notoriously negligent about filling out metadata fields. For free content, with few exceptions (notably MIT Open Courseware), there is no infrastructure for anybody else to do the cataloging. Thus, this type of static metadata is essentially useless, and educators cannot find the content they need.
The solution for this problem could be surprisingly simple: dynamic metadata based on crowdsourcing. As educators identify and sequence content resources for their teaching venues, this information is stored alongside the resources, e.g., "this resource was used before this other resource in this context and in this course." This usage-based dynamic metadata is gathered without any additional work for the educator or the author. The repository "learns" its content, and the next educator using the system gets recommendations based on other educators' choices: "people who bought this also bought that." Simple? No, currently impossible, because the deployment of a resource is usually disconnected from the repository: content is downloaded from a repository and uploaded into a course management system (CMS), where it is sequenced and deployed. There is no feedback loop.
Hurdle 2: Quality Control
Quality control has traditionally been the forte of publishing companies: editors and reviewers carefully go over the content to eliminate not only typos, but thoroughly check facts, formulations, and conceptual correctness. Errors in the materials can be very painful when teaching a class, particularly when it comes to homework or exams. Educators thus place high value on quality control. Once again, OERs are at an apparent disadvantage, usually lacking editorial staff. Some repositories thus resort to explicit peer review — generally a good approach, but not a scalable one.
If an educator chooses a resource, that also is peer review. This type of peer review is not punitive in nature; instead, it provides explicit peer approval and only implicitly the lack thereof. If many students in many courses work successfully through the resource, reliability is established. Particularly for assessment resources, difficulty, time-on-task, and other analytics can be gathered to establish their reliability and viability. If explanatory content is used in the context of assessment content, learning effectiveness can be established by looking at intervening content accesses between failed and successful attempts to solve a problem, essentially data-mining the access paths. All of this data once again contributes to the dynamic metadata of the resources to establish quality and search rankings. Simple? No, currently impossible, because once again deployment is disconnected from the repository. Once again, there is no feedback loop (see figure 1).
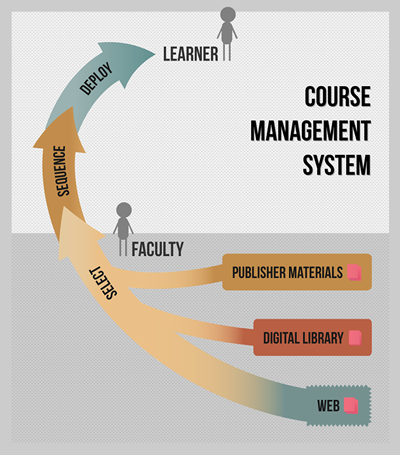
Illustration: Hwamok Park
Figure 1. OER use as a one-way street. Downloaded OERs get uploaded, sequenced, and deployed in a CMS, frequently without any assessment of learning success. No information flows back to the original asset.
Ask an OER provider how much impact they have — how many learners they actually reach with their content — and they usually don't know. Cannot know, really. One download could mean thousands of learners, or zero if the faculty member subsequently decides to not use the content after all.
The disconnect has yet another consequence: If a mistake is found in a resource and corrected, the downloaded copy inside of some CMS is still wrong. There is no way to push the improved version of a resource to the learners, so even if there is quality control, its fruits do not necessarily reach the learners. One can circumvent this particular problem by linking directly into the repository, but aside from the problem of possible stale links, assessment in turn could not send performance data to the course's grade book — the disconnect goes both ways.
Hurdle 3: Last Mile
For the vast majority of course topics, all of the information that would be in textbooks is freely available in online format. But this information is scattered, embedded into other contexts, or of the wrong granularity — how can an instructor serve it to students in an organized fashion, coupled with meaningful assessment? Traditional insular CMSs offer little assistance; they represent a bottleneck on the last mile between OERs and learners. The process of downloading content from a repository and uploading it to a course management infrastructure, besides being clumsy, is not necessarily in the skill repertoire of the average faculty member. Also, in many repositories, content already exists in context: there are menus, links to other content, branding features, even banner ads. Without major effort (at times prohibited by copyright or restrictive licenses), this content cannot be disentangled from its habitat. Leaving the repository's context in place, however, will likely have students drifting off into cyberspace. For content to be truly reusable and remixable, it needs to be context-free. The CMS should establish the context: sequencing, menus, and branding.
Formative assessment content should be embedded into explanatory content so that both learners and educators get meaningful feedback as they work through the curriculum. Graded formative assessment should be embedded into the materials and feed directly into the grade book — the content should drive and control the CMS, not the other way around.
In this podcast (8:04 minutes) Peter Riegler, professor of informatics and director of the Center for Successful Teaching and Learning, Ostfalia University of Applied Science, talks about formative assessment using web-based resources and grading.
Implementing these concepts moves course management to true learning content management. For OERs in particular, educators select content resources from multiple authors across multiple institutions, and the content immediately becomes available to learners with CMS navigation and grade book integration (figure 2).
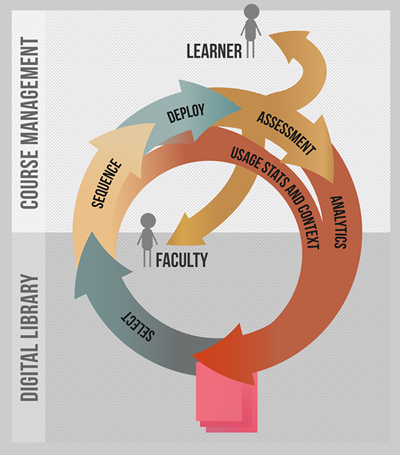
Illustration: Hwamok Park
Figure 2. Closing the loop. In an integrated system, usage data and analytics can flow back to the original asset at every stage. These provide quality measures and a basis for recommendation systems. Formative assessment from embedded problems is available to both learners and faculty in a timely manner.
Hurdle 4: Acquisition
For OERs to make a difference in traditional higher education requires convincing traditional higher education faculty to contribute teaching materials. But — either the OER movement is ahead of its time, or its pure ideology is unrealistic. Or perhaps the majority of faculty have a different understanding or expectation of "openness" that keeps them from contributing. It is thus worthwhile looking at definitions of "openness" and then at associated sources of faculty reluctance.
The authority on "openness" is Creative Commons, which is also 10 years old. The organization provides open licenses that codify the legal rights to reuse, revise, remix, and redistribute educational resources. To be an OER, a resource must be in the public domain or released under an open license that permits its free use and repurposing by others. Here, "public" or "others" includes learners, which is one of two major sources of faculty anxiety: What about homework, exam, and other assessment content? Can students see exam content? Can they see homework solutions, and can they publish solution guides?
One may argue that if an assessment outcome boils down to a simple, shareable answer key, it is not authentic and not addressing any real-world problems. Most faculty would agree, but what can instructors do when they have 300 students in a lecture hall and little or no assistance in grading?
What faculty might expect here is another kind of "openness" — open to their peers, i.e., other faculty. They in turn can assign assessment content, but faculty still control what students see. Assessment content, particularly if electronically graded, is not "open source." A repository must not only preserve the integrity of the entrusted content but also has stewardship obligations. Current OER licenses have no provision for this kind of openness, and repositories have no way of enforcing them when content is deployed outside these systems. To address this concern, the platform also needs to provide a means for controlling roles and privileges, so that the identity of content gatekeepers can be verified.
Another source of faculty unease is professional credit. Journals have impact factors and citation indices, and textbooks have sales figures, but OERs thrown out into the open have none of these. When it comes to annual evaluation time, even if the educational materials license requires attribution, there is no reporting back of actual impact. Additional anxiety is caused by the possibility of derivative works: who keeps track of the trail, once the materials have left the repository? Thus, once again, the disconnect between repository and deployment becomes a hindrance to wider use.
Why We Should Care Today
A decade into their existence, OERs could get a second wind: textbooks are morphing from traditional print to digital, and the strange phenomenon of massive open online courses (MOOCs) has emerged. These developments, essentially disconnected, could be unified and advanced by OERs.
E-texts: A Transitional Technology
Despite a number of exploratory efforts, textbook publishers in general have not successfully shifted from traditional print texts to interactive, engaging, modular, remixable digital texts. Many also provide their digital texts on proprietary platforms to retain control of usage and sales, with the side effect of hampering development of a resale market for digital textbooks. The current situation is similar to the transition the music industry underwent when CDs, like today's textbooks, were clearly on their way out. Music publishers scrambled to establish proprietary online music stores and their own versions of digital rights management, only to eventually be strong-armed in Apple's iTunes mechanism: a streamlined, end-to-end solution for marketing granular music content.
The flaws in the textbook market are clear, as is the solution: An outside player needs to provide a platform for content from various sources (faculty, grant projects, publishers, etc.) to be shared under common licensing schemes, including the means to sell content on a fine granularity level. In this model, faculty put together online course packs. They could choose and sequence content at granularity levels anywhere from individual pages or problems to whole chapters or modules, or even to complete prefabricated course packs, depending on how much work they want to invest in individualizing their materials. Students would buy access to these course packs at a price that depended on the contents, and the "player-device" (an iPod in the music-world example) would be the integrated CMS. The service provider for this system would collect the fees from students and distribute them to the content providers. If a particular course pack only contained OER content, it would be free.
MOOCs: Quo Vadis?
MOOCs could be a natural habitat for OERs, but currently are not. In a likely scenario, these MOOCs eventually might be integrated back into traditional efforts, just as the virtual universities eventually led to new models like blended and hybrid courses; the difference might simply be that different learner groups get different credentials for the same venue. Today's MOOCs make limited use of OERs — most content is custom-produced and not openly licensed. It is still unclear whether the current MOOCs will become sustainable. Given a viable platform that can serve both traditional for-credit courses and MOOCs, OERs might find a new habitat. And MOOCs might produce massive dynamic metadata and analytics that can feed back into the quality of on-campus instruction.
A Solution
The vision outlined here is not new. It goes back to a 2003 EDUCAUSE National Learning Infrastructure Initiative workgroup on the Next Generation Course Management System — but no such system has emerged in the intervening decade. Why?
Feasibility
The first question to answer is whether a "supersized" CMS is feasible.
- Perhaps such a monolith of learning content repository, sequencing tools, e-commerce, integrated course management, and feedback mechanisms is just too ambitious to build. Nonetheless, all these pieces must be in place for the system to work.
- People might argue that there is no room for a new CMS, but recent consolidation of the commercial market and the demise of some open-source systems might open up space in this realm. Besides, this is not just another insular CMS; it clearly functions outside the course container and beyond institutional boundaries.
- There are privacy concerns: a cross-institutional system cannot lead to private student data in places where it has no business. Depending on an institution's interpretation of FERPA or other applicable laws, student data may not even leave campus, and a hybrid model between local installations (possibly in the form of appliances) and global infrastructure and services is needed.
I still believe that such a system is possible and desirable:
- Educators will be able to identify and sequence the best of granular open, proprietary, and commercial content into educational playlists for their learners.
- As educators contribute, reuse, and remix content, they will build educational experiences that differ fundamentally from static e-texts: dynamic online course packs that combine targeted and proven learning content with effective assessment and analytics.
- Building on the power of data mining, crowdsourcing, and social networking, the platform will form, nurture, and support collaborative communities of practice of educators around the world.
- The system will provide an end-to-end solution from digital library functions, digital rights management, e-commerce, recommendation and sequencing tools, all the way to the course management functionality required to immediately deploy the online course packs: streamlined, efficient, reliable.
Such a system provides a habitat for OERs, an ecological system in which they can thrive alongside other species of educational content.
Existing Model System
A model system does exist. The LON-CAPA system established in 1999 is currently used at 160 different institutions. It implements all layers of the architecture described and currently hosts 440,000 reusable learning resources, including 200,000 randomizing online problems.
So far, 7,700 courses have relied on this resource pool, producing a significant amount of dynamic metadata. There is de-identified analytics data from 138 million assessment transactions, and over 2.8 million weighted association rules between content resources were extracted. This led to a use-based taxonomy and a prototype recommender system. Clearly, dynamic metadata is far richer than any kind of static metadata attached to content resources.
Ray Batchelor, senior lecturer in chemistry at Simon Fraser University, explains the appeal:
"The vision of building a course from modular content from many sources is very appealing. As a long-time user of LON-CAPA, I have observed how important is the facility for users to locate and analyze such modular content, in order to weave it into their courses. One frequently finds, however, that individual instructors may have very fine-grained needs or preferences, which may preclude them from using any specific resource, so located. In such an instance, it is nonetheless of great value for them to be able to use the remotely located resource as a model or template upon which to base their own self-authored content. Thus, as found in LON-CAPA, the facility remains vital for authors to release their original source code, in a controlled fashion to specified users, as well as to use the integrated communication tools — which enable remote author-instructors to easily consult over automatically cited, hyperlinked, or included resource content in their messages.
"The tools to search and analyze meta-data, and particularly dynamic meta-data, are a decided boon even when one is re-using their OWN, published content. For example, when producing exams, in LON-CAPA, I have often created diverse versions of essentially the same exam question to be used by different instructors, in different courses, with different detailed requirements as to how the question is to be worded and which additional fine-grained content is to be included. To be able to quickly determine whether or not a particular rendition of such a question best suits the present need, the previous usage history and summary statistics are invaluable."
What I propose here is a global enterprise-level system, which immediately raises the question, "How can such a system be financed in the long run, particularly if it is supposed to host free and open content?" The answer is probably manifold:
- Because the system also provides a marketplace for licensed resources, the entity operating it would probably take a cut from all mediated content sales.
- There might be a membership fee for an institution to supply part of the content pool.
- In addition, revenue can be generated from services such as hosting or local integration.
In the end, the business plan must make sense — it is naïve to believe that OERs can be free for everybody involved. Somebody has to pay for their creation, programming of the platform that hosts them, the platform's maintenance, the server space, the service, etc. Even if the content were originally generated using taxpayer money, in which case it arguably should be available for free, stewardship responsibilities — and their costs — continue. The business plan cannot rely on the same traditional institutions that face so many digital challenges already. Instead, the educational community can and should build a healthy, sustainable economy around OERs and commercial content, avoiding the excesses and idiosyncrasies of the current content marketplace. In a preferred model, the "supersized CMS" is open source and free; it should be as intuitive as an iPod, but it is only the "player-device." The entity that provides the marketplace, the service, and the support and keeps the whole enterprise moving forward is probably best implemented as a traditional company.
© 2013 Gerd Kortemeyer. The text of this EDUCAUSE Review Online article is licensed under the Creative Commons Attribution 3.0 license.